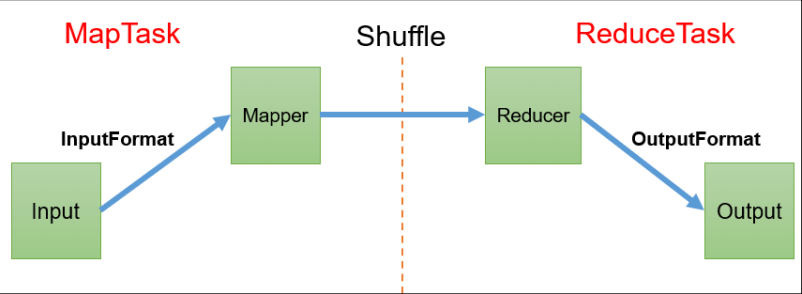
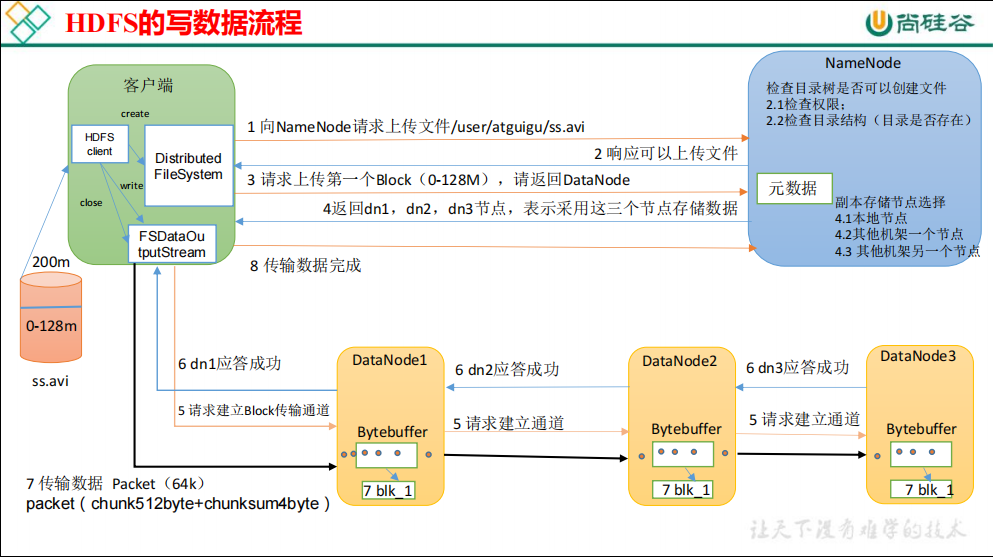
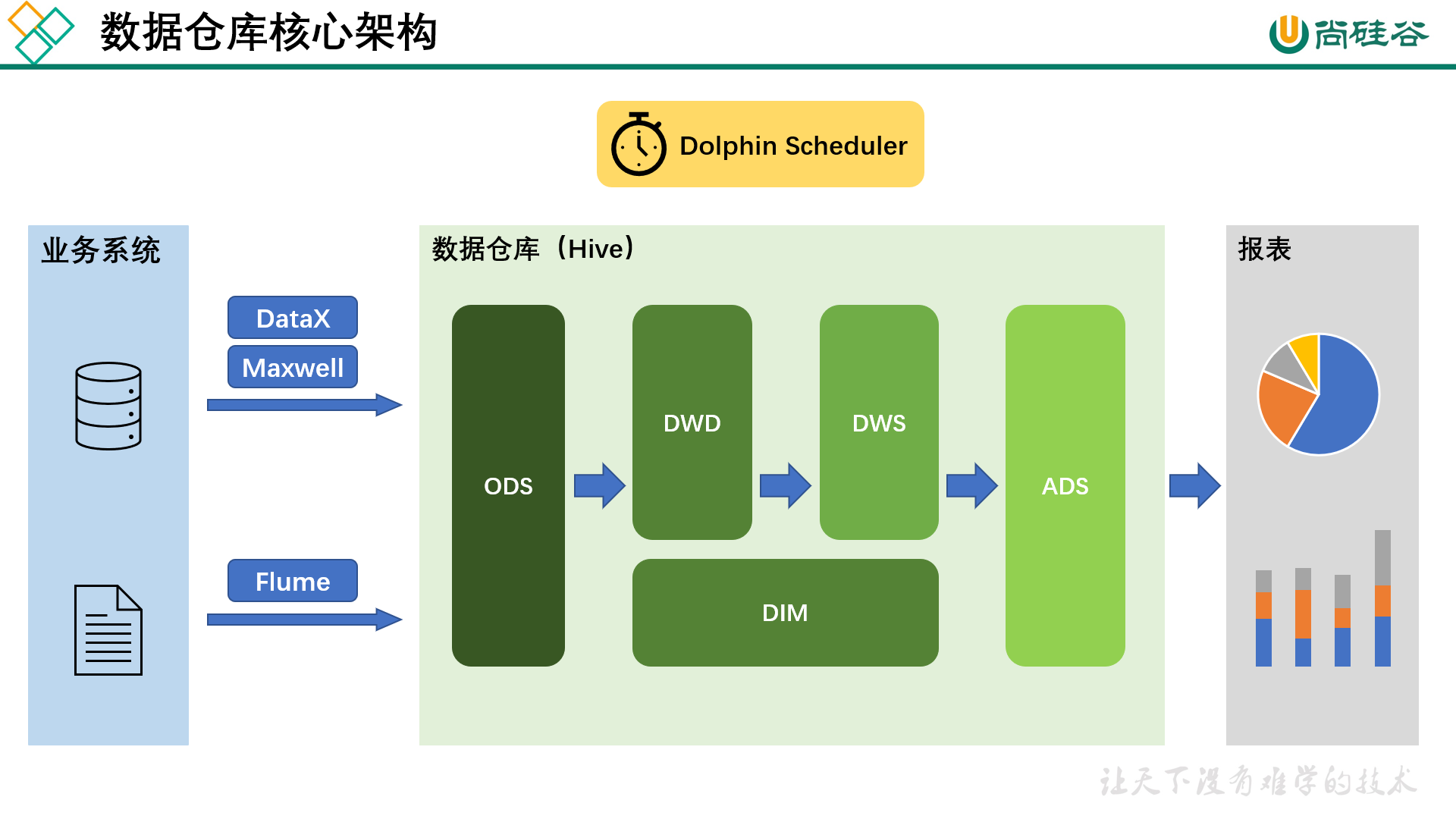
本文为学习笔记,对应视频教程来自尚硅谷大数据Hadoop教程(Hadoop 3.x安装搭建到集群调优)P59
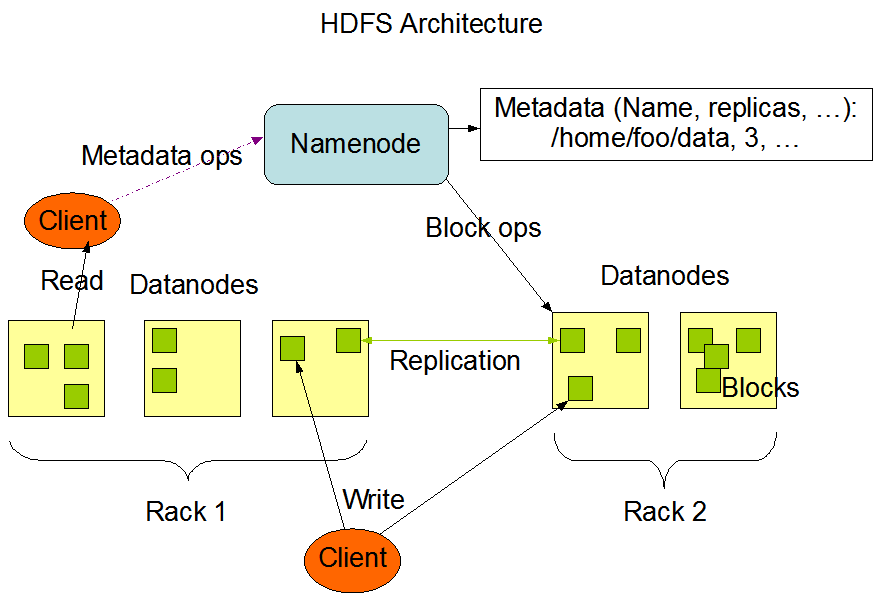
NameNode介绍
官方文档的介绍
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
HDFS 具有主/从架构。一个 HDFS 集群包含一个 NameNode,这是一个管理文件系统命名空间和控制客户端对文件的访问的主服务器。此外,还有许多 DataNode,通常集群中每个节点一个,用于管理它们运行的节点的存储。HDFS 公开了一个文件系统命名空间,并允许将用户数据存储在文件中。在内部,一个文件被分成一个或多个块,这些块存储在一组 DataNode 中。NameNode 执行文件系统命名空间操作,例如打开、关闭和重命名文件和目录。它还确定块到 DataNode 的映射。DataNode 负责处理来自文件系统客户端的读取和写入请求。DataNodes 还负责块创建、删除、根据NameNode的指示进行复制。