Hadoop(四):Hive
本文为学习笔记,对应视频教程来自黑马程序员Hive教程
Hive函数入门
函数概述
1 | -- 显示所有的函数和运算符 |
内置函数
String Functions 字符串函数
1 | -- 字符串长度函数:length(str | binary) |
Date Functions 日期函数
1 | -- 获取当前日期: current_date |
Mathematical Functions 数学函数
1 | -- 取整函数: round 返回double类型的整数值部分 (遵循四舍五入) |
Collection Functions 集合函数
1 | -- 集合元素size函数: size(Map<K.V>) size(Array<T>) |
Conditional Functions 条件函数
1 | -- 使用之前课程创建好的t_student表数据 |
Type Conversion Functions 类型转换函数
1 | -- 任意数据类型之间转换:cast |
Data Masking Functions 数据脱敏函数
1 | -- mask |
其他函数
1 | -- hive调用java方法: java_method(class, method[, arg1[, arg2..]]) |
用户自定义函数
UDF 普通函数
UDF函数通常把它叫做普通函数,最大的特点是一进一出,也就是输入一行输出一行。
UDAF 聚合函数
UDAF函数通常把它叫做聚合函数,A所代表的单词就是Aggregation聚合的意思。最大的特点是多进一出,也就是输入多行输出一行。
UDTF 表生成函数
UDTF函数通常把它叫做表生成函数,T所代表的单词是Table-Generating表生成的意思。最大的特点是一进多出,也就是输入一行输出多行。
案例:用户自定义UDF
需求描述
自定义开发实现Hive函数,对手机号机号中间4位进行****处理。
- 能够对输入数据进行非空判断、位数判断处理
- 能够实现校验手机号格式,把满足规则的进行处理
- 对于不符合手机号规则的数据原封不动不处理
实践
开发环境准备
创建Maven工程,添加下述pom依赖:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43<!-- 导入 hive 对应版本的依赖 -->
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>
<!-- 打包插件 -->
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>编写处理逻辑代码
写一个java类,继承UDF,并重载evaluate方法;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101package cn.itcast.hive.udf;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorConverters;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorConverter;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
/**
* 当Hive解析query时,会得到传入UDF参数的参数类型,并调用initialize()方法。
* 针对该UDF的每个参数该方法都会收到一个对应的ObjectInspector参数,且该方法必须返回一个ObjectInspector表示返回值类型。
* 通过调用该方法,Hive知道该UDF将返回什么数据类型,因此可以继续解析query。
* 对于Hive的每行记录,我们在initialize()方法内读取ObjectInspector参数,并执行传参的数量和数据类型的检查,正确时才进行计算;
* 在evaluate()方法中,我们使用initialize()方法里收到的ObjectInspector去读evaluate()方法接收的参数,
* 即一串泛型Object(实际是DeferredObject),ObjectInspector解析Object并转成具体类型的对象执行数据处理,最后输出结果。
*/
public class EncryptPhoneNumber extends GenericUDF {
private String udfName = "ENCRYPT_PHONUM";
private transient PrimitiveObjectInspectorConverter.TextConverter converter;
private Text result = new Text();
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length != 1) {
throw new UDFArgumentException(udfName + " requires one value argument. Found :"
+ arguments.length);
}
PrimitiveObjectInspector argumentOI;
if(arguments[0] instanceof PrimitiveObjectInspector) {
argumentOI = (PrimitiveObjectInspector) arguments[0];
} else {
throw new UDFArgumentException(udfName + " takes only primitive types. found "
+ arguments[0].getTypeName());
}
switch (argumentOI.getPrimitiveCategory()) {
case STRING:
case CHAR:
case VARCHAR:
break;
default:
throw new UDFArgumentException(udfName + " takes only STRING/CHAR/VARCHAR types. Found "
+ argumentOI.getPrimitiveCategory());
}
converter = new PrimitiveObjectInspectorConverter.TextConverter(argumentOI);
return PrimitiveObjectInspectorFactory.writableStringObjectInspector;
}
public Object evaluate(DeferredObject[] arguments) throws HiveException {
Object valObject = arguments[0].get();
if (valObject == null) {
return null;
}
String val = ((Text) converter.convert(valObject)).toString();
if (val == null) {
return null;
}
result.set(encryptPhonum(val.toString()));
return result;
}
//1. 能够对输入数据进行非空判断、位数判断处理
//2. 能够实现校验手机号格式,把满足规则的进行处理
//3. 对于不符合手机号规则的数据原封不动不处理
private String encryptPhonum(String phoNum) {
String encryptPhoNum = null;
// 手机号不为空 并且为11位
if (StringUtils.isNotEmpty(phoNum) && phoNum.trim().length() == 11 ) {
//判断数据是否满足中国大陆手机号码规范
String regex = "^(1[3-9]\\d{9}$)";
Pattern p = Pattern.compile(regex);
Matcher m = p.matcher(phoNum);
if (m.matches()) {//进入这里都是符合手机号规则的
//使用正则替换 返回加密后数据
encryptPhoNum = phoNum.trim().replaceAll("()\\d{4}(\\d{4})","$1****$2");
}else{
//不符合手机号规则 数据直接原封不动返回
encryptPhoNum = phoNum;
}
}else{
//不符合11位 数据直接原封不动返回
encryptPhoNum = phoNum;
}
return encryptPhoNum;
}
public String getDisplayString(String[] children) {
return "This is encrypt_phonum";
}
}参考内置的GenericUDFBaseTrim
将项目打包上传到hiveserver2服务器的家目录下
1
2
3
4
5
6
7[eitan@hadoop103 ~]$ ll
总用量 116120
drwxrwxr-x. 2 eitan eitan 4096 5月 12 16:09 bin
drwxrwxr-x. 3 eitan eitan 4096 5月 13 10:15 documents
-rw-rw-r--. 1 eitan eitan 118888832 5月 14 23:54 hive-example-1.0-SNAPSHOT.jar
drwxr-xr-x. 3 eitan eitan 4096 5月 13 21:55 hive_export
drwxrwxr-x. 2 eitan eitan 4096 5月 12 16:08 log使用命令把jar包添加至classpath
1
ADD JAR /home/eitan/hive-example-1.0-SNAPSHOT.jar;
注册临时函数
1
CREATE TEMPORARY FUNCTION encrypt_phonum AS 'cn.itcast.hive.udf.EncryptPhoneNumber';
使用效果
1
2
3
4-- 10086
SELECT encrypt_phonum("10086");
-- ****5338730
SELECT encrypt_phonum("18905338730");
Hive函数高级
explode函数
功能介绍
- explode接收map、array类型的数据作为输入,然后把输入数据中的每个元素拆开变成一行数据,一个元素一行;
- lexplode执行效果正好满足于输入一行输出多行,所有叫做UDTF函数。
简单使用
1 | SELECT explode(`array`(11,22,33)) AS item; |
explode使用限制及原因
限制:在select的时候,explode的旁边不支持其他字段的同时出现
原因:
- explode函数属于UDTF函数,即表生成函数;
- explode函数执行返回的结果可以理解为一张虚拟的表,其数据来源于源表;
- 在select中只查询源表数据没有问题,只查询explode生成的虚拟表数据也没问题
- 但是不能在只查询源表的时候,既想返回源表字段又想返回explode生成的虚拟表字段
- 通俗点讲,有两张表,不能只查询一张表但是返回分别属于两张表的字段;
- 从SQL层面上来说应该对两张表进行关联查询
- Hive专门提供了语法lateral View侧视图,专门用于搭配explode这样的UDTF函数,以满足上述需要。
Lateral View侧视图
概念及原理
- Lateral View是一种特殊的语法,主要用于搭配UDTF类型功能的函数一起使用,用于解决UDTF函数的一些查询限制的问题;
- 将UDTF的结果构建成一个类似于视图的表,然后将原表中的每一行和UDTF函数输出的每一行进行连接,生成一张新的虚拟表;
- 使用lateral view时也可以对UDTF产生的记录设置字段名称,产生的字段可以用于group by、order by 、limit等语句中,不需要再单独嵌套一层子查询。

语法
1 | --lateral view侧视图基本语法如下 |
案例
有一份数据《The_NBA_Championship.txt》,关于部分年份的NBA总冠军球队名单:
1 | Chicago Bulls,1991|1992|1993|1996|1997|1998 |
需求:使用Hive建表映射成功数据,对数据拆分,并且根据年份的倒序进行排序。
实践:
1 | -- step1 建表 |
Aggregation 聚合函数
基础聚合函数
1 | SELECT * FROM t_student; |
增强聚合函数
增强聚合的GROUPING SETS、CUBE、ROLLUP这几个函数主要适用于OLAP多维数据分析模式中,多维分析中的维指的分析问题时看待问题的维度、角度。
准备数据 字段:月份、天、用户cookieid
1
2
3
4
5
6
7
8
9
10
11
12
13
142018-03,2018-03-10,cookie1
2018-03,2018-03-10,cookie5
2018-03,2018-03-12,cookie7
2018-04,2018-04-12,cookie3
2018-04,2018-04-13,cookie2
2018-04,2018-04-13,cookie4
2018-04,2018-04-16,cookie4
2018-03,2018-03-10,cookie2
2018-03,2018-03-10,cookie3
2018-04,2018-04-12,cookie5
2018-04,2018-04-13,cookie6
2018-04,2018-04-15,cookie3
2018-04,2018-04-15,cookie2
2018-04,2018-04-16,cookie1表创建并加载数据
1
2
3
4
5
6
7
8
9CREATE TABLE cookie_info
(
month STRING,
day STRING,
cookieid STRING
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
LOAD DATA LOCAL INPATH "/home/eitan/documents/txt/cookie_info.txt" INTO TABLE cookie_info;GROUPING SETS
GROUPING SETS是一种将多个group by逻辑写在一个sql语句中的便利写法。等价于将不同维度的GROUP BY结果集进行UNION ALL。GROUPING__ID表示结果属于哪一个分组集合。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33SELECT month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month, day
GROUPING SETS ( month, day)
ORDER BY GROUPING__ID;
-- GROUPING__ID表示这一组结果属于哪个分组集合,
-- 根据grouping sets中的分组条件month,day,1是代表month,2是代表day
-- 等价于
SELECT month, NULL, COUNT(DISTINCT cookieid) AS nums, 1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL as month, day, COUNT(DISTINCT cookieid) AS nums, 2 AS GROUPING__ID FROM cookie_info GROUP BY day;
-- 再比如
SELECT month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month, day
GROUPING SETS ( month, day, ( month, day))
ORDER BY GROUPING__ID;
-- 等价于
SELECT month, NULL, COUNT(DISTINCT cookieid) AS nums, 1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL, day, COUNT(DISTINCT cookieid) AS nums, 2 AS GROUPING__ID FROM cookie_info GROUP BY day
UNION ALL
SELECT month, day, COUNT(DISTINCT cookieid) AS nums, 3 AS GROUPING__ID FROM cookie_info GROUP BY month, day;CUBE
CUBE的语法功能指的是:根据GROUP BY的维度的所有组合进行聚合。对于CUBE,如果有n个维度,则所有组合的总个数是:2^n。比如CUBE有a,b,c3个维度,则所有组合情况是: ((a,b,c),(a,b),(b,c),(a,c),(a),(b),(c),())。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
WITH CUBE
ORDER BY GROUPING__ID;
-- 等价于
SELECT NULL,NULL,COUNT(DISTINCT cookieid) AS nums,0 AS GROUPING__ID FROM cookie_info
UNION ALL
SELECT month,NULL,COUNT(DISTINCT cookieid) AS nums,1 AS GROUPING__ID FROM cookie_info GROUP BY month
UNION ALL
SELECT NULL,day,COUNT(DISTINCT cookieid) AS nums,2 AS GROUPING__ID FROM cookie_info GROUP BY day
UNION ALL
SELECT month,day,COUNT(DISTINCT cookieid) AS nums,3 AS GROUPING__ID FROM cookie_info GROUP BY month,day;ROLLUP
CUBE的语法功能指的是:根据GROUP BY的维度的所有组合进行聚合。
ROLLUP是Cube的子集,以最左侧的维度为主,从该维度进行层级聚合。比如ROLLUP有a,b,c3个维度,则所有组合情况是:((a,b,c),(a,b),(a),())。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22--rollup-------------
--比如,以month维度进行层级聚合:
SELECT
month,
day,
COUNT(DISTINCT cookieid) AS nums,
GROUPING__ID
FROM cookie_info
GROUP BY month,day
WITH ROLLUP
ORDER BY GROUPING__ID;
--把month和day调换顺序,则以day维度进行层级聚合:
SELECT
day,
month,
COUNT(DISTINCT cookieid) AS uv,
GROUPING__ID
FROM cookie_info
GROUP BY day,month
WITH ROLLUP
ORDER BY GROUPING__ID;
Window functions 窗口函数
概述
- 窗口函数(Window functions)也叫做开窗函数、OLAP函数,其最大特点是:输入值是从SELECT语句的结果集中的一行或多行的“窗口”中获取的。
- 如果函数具有OVER子句,则它是窗口函数。
- 窗口函数可以简单地解释为类似于聚合函数的计算函数,但是通过GROUP BY子句组合的常规聚合会隐藏正在聚合的各个行,最终输出一行,窗口函数聚合后还可以访问当中的各个行,并且可以将这些行中的某些属性添加到结果集中。
语法
1 | Function(arg1,..., argn) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_expression>]) |
其中Function(arg1,…, argn) 可以是下面分类中的任意一个
- 聚合函数:比如sum max avg等
- 排序函数:比如rank row_number等
- 分析函数:比如lead lag first_value等
OVER [PARTITION BY <…>] 类似于group by 用于指定分组 每个分组你可以把它叫做窗口
如果没有PARTITION BY 那么整张表的所有行就是一组
[ORDER BY <….>] 用于指定每个分组内的数据排序规则 支持ASC、DESC
[
] 用于指定每个窗口中 操作的数据范围 默认是窗口中所有行
实践
建表并导入数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18CREATE TABLE website_pv_info
(
cookieid string,
createtime string,
pv int
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
CREATE TABLE website_url_info
(
cookieid string,
createtime string, --访问时间
url string --访问页面
) ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
LOAD DATA LOCAL INPATH "/home/eitan/documents/txt/website_pv_info.txt" INTO TABLE website_pv_info;
LOAD DATA LOCAL INPATH "/home/eitan/documents/txt/website_url_info.txt" INTO TABLE website_url_info;窗口聚合函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24-- 1、求出每个用户总pv数 sum+group by普通常规聚合操作
SELECT cookieid,sum(pv) AS total_pv FROM website_pv_info GROUP BY cookieid;
-- 2、sum+窗口函数 总共有四种用法 注意是整体聚合 还是累积聚合
-- sum(...) over( )对表所有行求和
-- sum(...) over( order by ... ) 连续累积求和
-- sum(...) over( partition by... ) 同组内所有行求和
-- sum(...) over( partition by... order by ... ) 在每个分组内,连续累积求和
-- 需求:求出网站总的pv数 所有用户所有访问加起来
-- sum(...) over( )对表所有行求和
SELECT cookieid,createtime,pv,
sum(pv) OVER() AS total_pv FROM website_pv_info;
-- 需求:求出每个用户总pv数
-- sum(...) over( partition by... ),同组内所行求和
SELECT cookieid,createtime,pv,
sum(pv) OVER (PARTITION BY cookieid) AS total_pv FROM website_pv_info;
-- 需求:求出每个用户截止到当天,累积的总pv数
-- sum(...) over( partition by... order by ... ),在每个分组内,连续累积求和
SELECT cookieid,createtime,pv,
sum(pv) OVER(PARTITION BY cookieid ORDER BY createtime) AS current_total_pv
FROM website_pv_info;窗口表达式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32关键字是rows between,包括下面这几个选项
- preceding:往前
- following:往后
- current row:当前行
- unbounded:边界
- unbounded preceding 表示从前面的起点
- unbounded following:表示到后面的终点
-- 第一行到当前行
SELECT cookieid,createtime,pv,
sum(pv) OVER (PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS pv2
FROM website_pv_info;
-- 向前3行至当前行
SELECT cookieid,createtime,pv,
sum(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW ) AS pv4
from website_pv_info;
-- 向前3行 向后1行
SELECT cookieid,createtime,pv,
sum(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING) AS pv5
FROM website_pv_info;
--当前行至最后一行
SELECT cookieid,createtime,pv,
sum(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS pv6
FROM website_pv_info;
--第一行到最后一行 也就是分组内的所有行
SELECT cookieid,createtime,pv,
sum(pv) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS pv6
FROM website_pv_info;窗口排序函数
窗口排序函数用于给每个分组内的数据打上排序的标号。注意窗口排序函数不支持窗口表达式。总共有4个函数需要掌握:
row_number:在每个分组中,为每行分配一个从1开始的唯一序列号,递增,不考虑重复;
rank: 在每个分组中,为每行分配一个从1开始的序列号,考虑重复,挤占后续位置;
dense_rank: 在每个分组中,为每行分配一个从1开始的序列号,考虑重复,不挤占后续位置;
ntile:将每个分组内的数据分为指定的若干个桶里(分为若干个部分),并且为每一个桶分配一个桶编号。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36SELECT
cookieid,
createtime,
pv,
RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn1,
DENSE_RANK() OVER(PARTITION BY cookieid ORDER BY pv desc) AS rn2,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn3
FROM website_pv_info
WHERE cookieid = 'cookie1';
-- 需求:找出每个用户访问pv最多的是哪天的Top3 重复并列的不考虑
SELECT * FROM
(SELECT cookieid,
createtime,
pv,
ROW_NUMBER() OVER (PARTITION BY cookieid ORDER BY pv DESC) AS seq FROM website_pv_info) tmp
WHERE tmp.seq < 4;
-- 把每个分组内的数据分为3桶 NTILE
SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY createtime) AS rn2
FROM website_pv_info
ORDER BY cookieid,createtime;
-- 需求:统计每个用户pv数最多的前3分之1天。
-- 理解:将数据根据cookieid分 根据pv倒序排序 排序之后分为3个部分 取第一部分
SELECT * FROM
(SELECT
cookieid,
createtime,
pv,
NTILE(3) OVER(PARTITION BY cookieid ORDER BY pv DESC) AS rn FROM website_pv_info) tmp
WHERE rn = 1;窗口分析函数
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
第一个参数为列名,第二个参数为往上第n行(可选,默认为1),第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL);
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值
第一个参数为列名,第二个参数为往下第n行(可选,默认为1),第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL);
FIRST_VALUE 取分组内排序后,截止到当前行,第一个值;
LAST_VALUE 取分组内排序后,截止到当前行,最后一个值;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34-- LAG
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAG(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS last_1_time,
LAG(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS last_2_time
FROM website_url_info;
-- LEAD
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LEAD(createtime,1,'1970-01-01 00:00:00') OVER(PARTITION BY cookieid ORDER BY createtime) AS next_1_time,
LEAD(createtime,2) OVER(PARTITION BY cookieid ORDER BY createtime) AS next_2_time
FROM website_url_info;
-- FIRST_VALUE
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
FIRST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS first1
FROM website_url_info;
-- LAST_VALUE
SELECT cookieid,
createtime,
url,
ROW_NUMBER() OVER(PARTITION BY cookieid ORDER BY createtime) AS rn,
LAST_VALUE(url) OVER(PARTITION BY cookieid ORDER BY createtime) AS last1
FROM website_url_info;
Sampling 抽样函数
Random随机抽样
随机抽样使用rand()函数和LIMIT关键字来获取数据。 使用了DISTRIBUTE和SORT关键字,可以确保数据也随机分布在mapper和reducer之间,使得底层执行有效率。
ORDER BY 和rand()语句也可以达到相同的目的,但是表现不好。因为ORDER BY是全局排序,只会启动运行一个Reducer。
1 | -- 需求:随机抽取2个学生的情况进行查看 |
Block块抽样
Block块采样允许select随机获取n行数据,即数据大小或n个字节的数据。采样粒度是HDFS块大小。
1 | ---block抽样 |
Bucket table分桶表抽样
这是一种特殊的采样方法,针对分桶表进行了优化。优点是既随机速度也很快。
语法如下:
1 | TABLESAMPLE (BUCKET x OUT OF y [ON colname]) |
- y必须是table总bucket数的倍数或者因子。hive根据y的大小,决定抽样的比例。
例如,table总共分了4份(4个bucket),当y=2时,抽取(4/2=)2个bucket的数据,当y=8时,抽取(4/8=)1/2个bucket的数据- x表示从哪个bucket开始抽取。
例如,table总bucket数为4,tablesample(bucket 4 out of 4),表示总共抽取(4/4=)1个bucket的数据,抽取第4个bucket的数据。
注意:x的值必须小于等于y的值,否则FAILED:Numerator should not be bigger than denominator in sample clause for table stu_buck- ON colname表示基于什么抽
ON rand()表示随机抽
ON 分桶字段 表示基于分桶字段抽样 效率更高 推荐
1 | ---bucket table抽样 |
Hive函数应用案例
多字节分隔符
应用场景
Hive中默认使用单字节分隔符来加载文本数据,但在实际工作中,我们遇到的数据往往不是非常规范化的数据,我们会遇到以下的两种情况:
每一行数据的分隔符是多字节分隔符,例如:”||”、“–”等
1
2
3
4
5
6
7
8
9
1001||周杰伦||中国||台湾||男||七里香
02||刘德华||中国||香港||男||笨小孩
03||汪 峰||中国||北京||男||光明
04||朴 树||中国||北京||男||那些花儿
05||许 巍||中国||陕西||男||故乡
06||张靓颖||中国||四川||女||画心
07||黄家驹||中国||香港||男||光辉岁月
08||周传雄||中国||台湾||男||青花
09||刘若英||中国||台湾||女||很爱很爱你
10||张 杰||中国||四川||男||天下数据的字段中包含了分隔符
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20192.168.88.134 [08/Nov/2020:10:44:32 +0800] "GET / HTTP/1.1" 404 951
192.168.88.100 [08/Nov/2020:10:44:33 +0800] "GET /hpsk_sdk/index.html HTTP/1.1" 200 328
192.168.88.134 [08/Nov/2020:20:19:06 +0800] "GET / HTTP/1.1" 404 951
192.168.88.100 [08/Nov/2020:20:19:13 +0800] "GET /hpsk_sdk/demo4.html HTTP/1.1" 200 982
192.168.88.100 [08/Nov/2020:20:19:13 +0800] "GET /hpsk_sdk/js/analytics.js HTTP/1.1" 200 11095
192.168.88.100 [08/Nov/2020:20:19:23 +0800] "GET /hpsk_sdk/demo3.html HTTP/1.1" 200 1024
192.168.88.100 [08/Nov/2020:20:19:26 +0800] "GET /hpsk_sdk/demo2.html HTTP/1.1" 200 854
192.168.88.100 [08/Nov/2020:20:19:27 +0800] "GET /hpsk_sdk/demo.html HTTP/1.1" 200 485
192.168.88.134 [08/Nov/2020:20:26:51 +0800] "GET / HTTP/1.1" 404 951
192.168.88.134 [08/Nov/2020:20:29:08 +0800] "GET / HTTP/1.1" 404 951
192.168.88.100 [08/Nov/2020:20:31:27 +0800] "GET /hpsk_sdk/demo5.html HTTP/1.1" 200 5333
192.168.88.100 [08/Nov/2020:20:32:59 +0800] "GET /hpsk_sdk/demo5.html HTTP/1.1" 200 5333
192.168.88.100 [08/Nov/2020:20:32:59 +0800] "GET /hpsk_sdk/js/analytics.js HTTP/1.1" 200 11082
192.168.88.100 [08/Nov/2020:20:32:59 +0800] "GET /favicon.ico HTTP/1.1" 404 973
192.168.88.100 [08/Nov/2020:20:33:01 +0800] "GET /hpsk_sdk/demo3.html HTTP/1.1" 200 1024
192.168.88.100 [08/Nov/2020:20:34:25 +0800] "GET /hpsk_sdk/demo2.html HTTP/1.1" 200 854
192.168.88.100 [08/Nov/2020:20:34:25 +0800] "GET /hpsk_sdk/js/analytics.js HTTP/1.1" 304 -
192.168.88.100 [08/Nov/2020:20:34:28 +0800] "GET /hpsk_sdk/demo4.html HTTP/1.1" 200 982
192.168.88.100 [08/Nov/2020:20:35:05 +0800] "GET /hpsk_sdk/demo.html HTTP/1.1" 200 485
192.168.88.100 [08/Nov/2020:20:35:05 +0800] "GET /hpsk_sdk/js/analytics.js HTTP/1.1" 304 -
解决方案一:替换分割符
如果数据中的分隔符是多字节分隔符,可以使用程序提前将数据中的多字节分隔符替换为单字节分隔符,然后使用Hive加载,就可以实现正确加载对应的数据。
创建Maven工程,编写对应MapReduce代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hive-example</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.2</version>
<configuration>
<!--只包含该项目代码中用到的jar,在父项目中引入了,但在当前模块中没有用到就会被删掉-->
<minimizeJar>true</minimizeJar>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51package cn.itcast.hadoop.changesplit;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 实现Tool接口,目的是为了 hadoop 命令调用保证可以传入一些与程序入参无关的命令行参数
* Configured的getConf获取环境变量实例
*/
public class ChangeSplitCharMR extends Configured implements Tool {
public int run(String[] strings) throws Exception {
// 1. 构建Job
Job job = Job.getInstance(this.getConf(), "changeSplit");
job.setJarByClass(ChangeSplitCharMR.class);
// 2. 配置Job
// input
job.setInputFormatClass(TextInputFormat.class);
Path inputPath = new Path(strings[0]);
FileInputFormat.setInputPaths(job, inputPath);
// map
job.setMapperClass(ChangeSplitMapper.class);
// 设置输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
// reduce:不需要 Reduce 过程
job.setNumReduceTasks(0);
// output
job.setOutputFormatClass(TextOutputFormat.class);
Path outputPath = new Path(strings[1]);
FileOutputFormat.setOutputPath(job, outputPath);
// 提交 job
return job.waitForCompletion(true) ? 0 : 1;
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new ChangeSplitCharMR(), args);
System.exit(status);
}
}1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21package cn.itcast.hadoop.changesplit;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ChangeSplitMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
private Text outputKey = new Text();
private NullWritable outputValue = NullWritable.get();
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
outputKey.set(line.replace("||","|"));
context.write(outputKey,outputValue);
}
}打包并上传
修改不带依赖的jar包为change-split.jar,并拷贝到虚拟机中
运行hadoop程序进行数据清洗
1
2
3
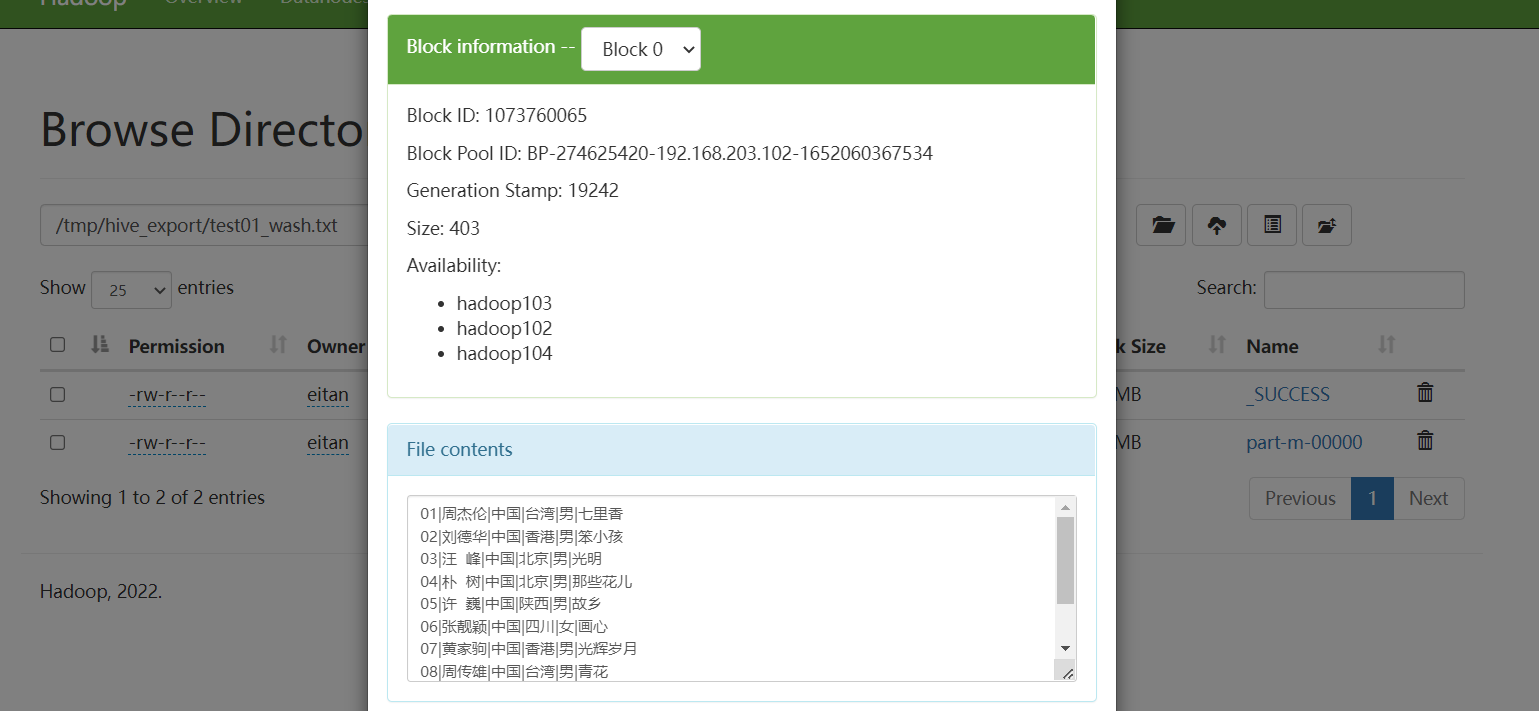
4[eitan@hadoop103 ~]$ hadoop fs -put documents/txt/test01.txt /tmp/hive_export
[eitan@hadoop103 ~]$ hadoop jar change-split.jar cn.itcast.hadoop.changesplit.ChangeSplitCharMR /tmp/hive_export/test01.txt /tmp/hive_export/test01_wash.txt结果
解决方案二:RegexSerDe正则加载
RegexSerde是Hive中专门为了满足复杂数据场景所提供的正则加载和解析数据的接口,使用RegexSerde可以指定正则表达式加载数据,根据正则表达式匹配每一列数据。
分析数据
1
192.168.88.100 [08/Nov/2020:10:44:33 +0800] "GET /hpsk_sdk/index.html HTTP/1.1" 200 328
正则表达式定义每一列
1
([^ ]*) ([^}]*) ([^ ]*) ([^ ]*) ([^ ]*) ([0-9]*) ([^ ]*)
创建表
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21--创建表
CREATE TABLE apachelog
(
ip string, --IP地址
stime string, --时间
mothed string, --请求方式
url string, --请求地址
policy string, --请求协议
stat string, --请求状态
body string --字节大小
)
--指定使用RegexSerde加载数据
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
--指定正则表达式
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^}]*) ([^ ]*) ([^ ]*) ([^ ]*) ([0-9]*) ([^ ]*)"
);
LOAD DATA INPATH "/tmp/hive_export/apache_web_access.log" INTO TABLE apachelog;
SELECT * FROM apachelog;
解决方案三:自定义InputFormat
暂无手动实现。
URL解析函数及侧视图
数据准备
1 | 1 http://facebook.com/path/p1.php?query=1 |
1 | CREATE TABLE IF NOT EXISTS t_url |
parse_url
1 | SELECT id, |
缺点:parse_url函数每次只能解析一个参数,导致需要经过多个函数调用才能构建多列,开发角度较为麻烦,实现过程性能也相对较差,需要对同一列做多次计算处理,我们希望能实现调用一次函数,就可以将多个参数进行解析,得到多列结果
parse_url_tuple
1 | SELECT a.id, |
行列转换应用
行转列:多行转多列
1 | -- 建表并导入数据 |
行转列:多行转单列
1 | -- 建表并导入数据 |
列转行:多列转多行
1 | -- 建表并导入数据 |
列转行:单列转多行
1 | -- 建表并导入数据 |
JSON数据处理
需求
将json文件每一个字段解析成对应的表字段
方法一:使用JSON解析函数
1 | -- 建表并导入数据 |
方法二:指定解析JSON的SerDe
1 | -- 创建表并指定序列化和反序列化的类 |
窗口函数应用实例
连续登陆用户
1 | -- 建表并加载数据 |
级联累加求和
1 | -- 建表加载数据 |
分组TopN
1 | -- 创建表并载入数据 |
拉链表的设计与实现
功能与应用场景
拉链表专门用于解决在数据仓库中数据发生变化如何实现数据存储的问题,如果直接覆盖历史状态,会导致无法查询历史状态,如果将所有数据单独切片存储,会导致存储大量非更新数据的问题。
拉链表的设计是将更新的数据进行状态记录,没有发生更新的数据不进行状态存储,用于存储所有数据在不同时间上的所有状态,通过时间进行标记每个状态的生命周期,查询时,根据需求可以获取指定时间范围状态的数据,默认用9999-12-31等最大值来表示最新状态。
拉链表实现
创建表并插入数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14CREATE TABLE dw_zipper
(
userid string,
phone string,
nick string,
gender int,
addr string,
starttime string,
endtime string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
LOAD DATA LOCAL INPATH "/home/eitan/documents/txt/zipper.txt" INTO TABLE dw_zipper;
SELECT * FROM dw_zipper;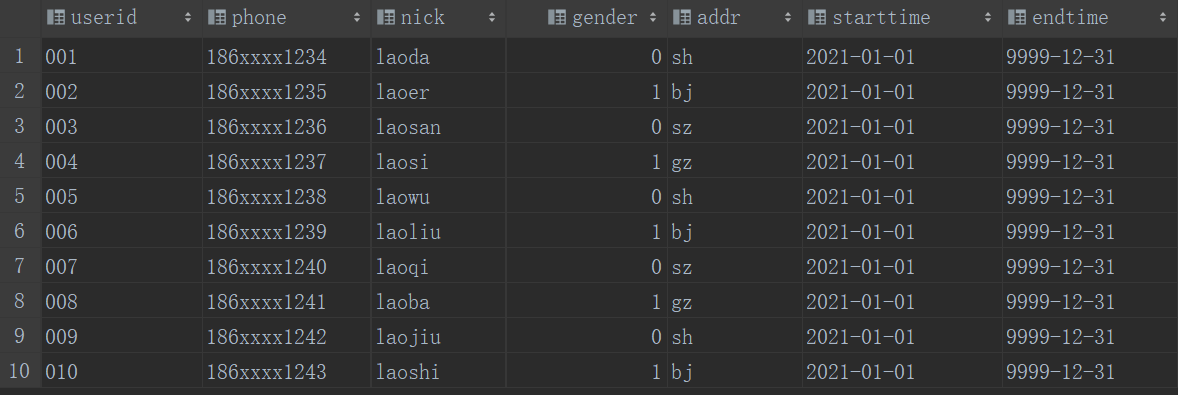
创建ods层增量表,模拟增量
1
2
3
4
5
6
7
8
9
10
11
12
13
14CREATE TABLE ods_zipper_update
(
userid string,
phone string,
nick string,
gender int,
addr string,
starttime string,
endtime string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
LOAD DATA LOCAL INPATH "/home/eitan/documents/txt/update.txt" INTO TABLE ods_zipper_update;
SELECT * FROM ods_zipper_update;
合并数据
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32-- 创建零时表
CREATE TABLE tmp_zipper
(
userid string,
phone string,
nick string,
gender int,
addr string,
starttime string,
endtime string
) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
-- 合并拉链表与增量表
INSERT OVERWRITE TABLE tmp_zipper
SELECT userid,
phone,
nick,
gender,
addr,
starttime,
endtime
FROM ods_zipper_update
UNION ALL
SELECT a.userid,
a.phone,
a.nick,
a.gender,
a.addr,
a.starttime,
if(b.userid IS NULL OR a.endtime < "9999-12-31", a.endtime, date_sub(b.starttime, 1)) AS endtime
FROM dw_zipper a
LEFT JOIN ods_zipper_update b ON a.userid = b.userid;覆盖拉链表
1
2INSERT OVERWRITE TABLE dw_zipper
SELECT * FROM tmp_zipper ORDER BY userid;
Hive性能优化
Hive表设计优化
分区表
根据查询的需求,将数据按照查询的条件【一般都以时间】进行划分分区存储,将不同分区的数据单独使用一个HDFS目录来进行存储,当底层实现计算时,根据查询的条件,只读取对应分区的数据作为输入,减少不必要的数据加载,提高程序的性能。
分桶表
分桶表的设计有别于分区表的设计,分区表是将数据划分不同的目录进行存储,而分桶表是将数据划分不同的文件进行存储。分桶表的设计是按照一定的规则【通过MapReduce中的多个Reduce来实现】将数据划分到不同的文件中进行存储,构建分桶表。
如果有两张表按照相同的划分规则【按照Join的关联字段】将各自的数据进行划分,在Join时,就可以实现Bucket与Bucket的Join,避免不必要的比较。
Hive表数据优化
文件格式
| 文件格式 | 优点 | 缺点 | 应用场景 |
|---|---|---|---|
| TextFIle(默认) | 1. 最简单的数据格式,不需要经过处理,可以直接查看 2. 可以使用任意的分隔符进行分割 3. 可以搭配Gzip、Bzip2、Snappy等压缩一起使用 |
1. 耗费存储空间,I/O性能较低 2. 结合压缩时Hive不进行数据切分合并,不能进行并行操作,查询效率低 3. 按行存储,读取列的性能差 |
1. 适合于小量数据的存储查询 2. 一般用于做第一层数据加载和测试使用 |
| SequenceFile | 1. 以二进制的KV形式存储数据,与底层交互更加友好,性能更快 2. 可压缩、可分割,优化磁盘利用率和I/O 3. 可并行操作数据,查询效率高 4. SequenceFile也可以用于存储多个小文件 |
1. 存储空间消耗最大 2. 与非Hadoop生态系统之外的工具不兼容 3. n 构建SequenceFile需要通过TextFile文件转化加载 |
1. 适合于小量数据,但是查询列比较多的场景 |
| Parquet | 1. 更高效的压缩和编码 2. 可用于多种数据处理框架 |
1. 不支持update, insert, delete, ACID | 1. 适用于字段数非常多,无更新,只取部分列的查询 |
| ORC(OptimizedRC File) | 1. 列式存储,存储效率非常高 2. 可压缩,高效的列存取 3. 查询效率较高,支持索引 4. 支持矢量化查询 |
1. 加载时性能消耗较大 2. 需要通过text文件转化生成 3. 读取全量数据时性能较差 |
1. 适用于Hive中大型的存储、查询 |
数据压缩
压缩的优点
- 减小文件存储所占空间
- 加快文件传输效率,从而提高系统的处理速度
- 降低IO读写的次数
压缩的缺点
- 使用数据时需要先对文件解压,加重CPU负荷,压缩算法越复杂,解压时间越长
压缩配置
1
2
3
4
5
6
7
8
9
10--开启输出压缩
set mapreduce.output.fileoutputformat.compress=true;
--配置压缩类型为Snappy
set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.SnappyCodec;
-- 中间结果压缩
set hive.exec.compress.intermediate=true;
set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.SnappyCodec;
-- 输出结果压缩
set hive.exec.compress.output=true;永久配置:
将以上MapReduce的配置写入mapred-site.xml中,重启Hadoop
将以上Hive的配置写入hive-site.xml中,重启Hive
存储优化
避免小文件的生成
1
2
3
4
5
6
7
8-- 如果hive的程序,只有maptask,将MapTask产生的所有小文件进行合并
set hive.merge.mapfiles=true;
-- 如果hive的程序,有Map和ReduceTask,将ReduceTask产生的所有小文件进行合并
set hive.merge.mapredfiles=true;
-- 每一个合并的文件的大小
set hive.merge.size.per.task=256000000;
-- 平均每个文件的大小,如果小于这个值就会进行合并
set hive.merge.smallfiles.avgsize=16000000;读取小文件
1
2-- 设置Hive中底层MapReduce读取数据的输入类:将所有文件合并为一个大文件作为输入
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;ORC文件索引
一个ORC文件包含一个或多个stripes(groups of row data),每个stripe中包含了每个column的min/max值的索引数据,当查询中有<,>,=的操作时,会根据min/max值,跳过扫描不包含的stripes。而其中为每个stripe建立的包含min/max值的索引,就称为Row Group Index行组索引。
为了使Row Group Index有效利用,向表中加载数据时,必须对需要使用索引的字段进行排序,否则,min/max会失去意义。另外,这种索引主要用于数值型字段的范围查询过滤优化上。
1
2
3
4
5
6
7
8
9
10
11
12-- 开启索引配置
set hive.optimize.index.filter=true;
-- 创建表,并指定构建索引
create table tb_sogou_orc_index
stored as orc tblproperties ("orc.create.index"="true")
as select * from tb_sogou_source
distribute by stime
sort by stime;
-- 当进行范围或者等值查询(<,>,=)时就可以基于构建的索引进行查询
select count(*) from tb_sogou_orc_index where stime > '12:00:00' and stime < '18:00:00';建表时候,通过表参数”orc.bloom.filter.columns”=”columnName……”来指定为哪些字段建立BloomFilter索引,这样,在生成数据的时候,会在每个stripe中,为该字段建立BloomFilter的数据结构,当查询条件中包含对该字段的=号过滤时候,先从BloomFilter中获取以下是否包含该值,如果不包含,则跳过该stripe。
1
2
3
4
5
6
7
8
9
10
11
12
13
14-- 创建表指定创建布隆索引
create table tb_sogou_orc_bloom
stored as orc tblproperties ("orc.create.index"="true","orc.bloom.filter.columns"="stime,userid")
as select * from tb_sogou_source
distribute by stime
sort by stime;
-- stime的范围过滤可以走row group index,userid的过滤可以走bloom filter index
select
count(*)
from tb_sogou_orc_index
where stime > '12:00:00' and stime < '18:00:00'
and userid = '3933365481995287' ;ORC矢量化查询
Hive的默认查询执行引擎一次处理一行,而矢量化查询执行是一种Hive针对ORC文件操作的特性,目的是按照每批1024行读取数据,并且一次性对整个记录整合(而不是对单条记录)应用操作,提升了像过滤, 联合, 聚合等等操作的性能。
注意:要使用矢量化查询执行,就必须以ORC格式存储数据。
1
2set hive.vectorized.execution.enabled = true;
set hive.vectorized.execution.reduce.enabled = true;
计算Job执行优化
Explain
常用语法命令如下:
1 | EXPLAIN [FORMATTED|EXTENDED|DEPENDENCY|AUTHORIZATION|] query |
- FORMATTED:对执行计划进行格式化,返回JSON格式的执行计划
- EXTENDED:提供一些额外的信息,比如文件的路径信息
- DEPENDENCY:以JSON格式返回查询所依赖的表和分区的列表
- AUTHORIZATION:列出需要被授权的条目,包括输入与输出
MapReduce属性优化
本地模式
使用Hive的过程中,有一些数据量不大的表也会转换为MapReduce处理,提交到集群时,需要申请资源,等待资源分配,启动JVM进程,再运行Task,一系列的过程比较繁琐,本身数据量并不大,提交到YARN运行返回会导致性能较差的问题。
Hive为了解决这个问题,延用了MapReduce中的设计,提供本地计算模式,允许程序不提交给YARN,直接在本地运行,以便于提高小数据量程序的性能。
1
2-- 开启本地模式
set hive.exec.mode.local.auto = true;如果以下任意一个条件不满足,那么即使开启了本地模式,将依旧会提交给YARN集群运行:
- 处理的数据量不超过128M
- MapTask的个数不超过4个
- ReduceTask的个数不超过1个
JVM重用
JVM正常指代一个Java进程,Hadoop默认使用派生的JVM来执行map-reducer,如果一个MapReduce程序中有100个Map,10个Reduce,Hadoop默认会为每个Task启动一个JVM来运行,那么就会启动100个JVM来运行MapTask,在JVM启动时内存开销大,尤其是Job大数据量情况,如果单个Task数据量比较小,也会申请JVM资源,这就导致了资源紧张及浪费的情况。
为了解决上述问题,MapReduce中提供了JVM重用机制来解决,JVM重用可以使得JVM实例在同一个job中重新使用N次,当一个Task运行结束以后,JVM不会进行释放,而是继续供下一个Task运行,直到运行了N个Task以后,就会释放,N的值可以在Hadoop的mapred-site.xml文件中进行配置,通常在10-20之间。
1
2
3-- Hadoop3之前的配置,在mapred-site.xml中添加以下参数
-- Hadoop3中已不再支持该选项
mapreduce.job.jvm.numtasks=10并行执行
Hive在实现HQL计算运行时,会解析为多个Stage,有时候Stage彼此之间有依赖关系,只能挨个执行,但是在一些别的场景下,很多的Stage之间是没有依赖关系的,例如Union语句,Join语句等等,这些Stage没有依赖关系,但是Hive依旧默认挨个执行每个Stage,这样会导致性能非常差,我们可以通过修改参数,开启并行执行,当多个Stage之间没有依赖关系时,允许多个Stage并行执行,提高性能。
1
2
3
4-- 开启Stage并行化,默认为false
SET hive.exec.parallel=true;
-- 指定并行化线程数,默认为8
SET hive.exec.parallel.thread.number=16;
Join优化
Map Join
1
2
3
4
5-- Hive中小表的大小限制
-- 2.0版本之前的控制属性
hive.mapjoin.smalltable.filesize=25M
-- 2.0版本开始由以下参数控制
hive.auto.convert.join.noconditionaltask.size=512000000Reduce Join
Bucket Join
Bucket Join
语法:clustered by colName
参数:set hive.optimize.bucketmapjoin = true;
要求:分桶字段 = Join字段 ,桶的个数相等或者成倍数
Sort Merge Bucket Join(SMB):基于有序的数据Join
语法:clustered by colName sorted by (colName)
参数:
1
2
3
4
5-- 开启分桶SMB join
set hive.optimize.bucketmapjoin = true;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
set hive.auto.convert.sortmerge.join.noconditionaltask=true;要求:分桶字段 = Join字段 = 排序字段 ,桶的个数相等或者成倍数
优化器
关联优化
1
2-- 对有关联关系的操作进行解析时,可以尽量放在同一个MapReduce中实现
set hive.optimize.correlation=true;优化引擎
RBO
- rule basic optimise:基于规则的优化器
- 根据设定好的规则来对程序进行优化
CBO
- cost basic optimise:基于代价的优化器
- 根据不同场景所需要付出的代价来合适选择优化的方案
- 对数据的分布的信息【数值出现的次数,条数,分布】来综合判断用哪种处理的方案是最佳方案
1
2
3
4set hive.cbo.enable=true;
set hive.compute.query.using.stats=true;
set hive.stats.fetch.column.stats=true;
set hive.stats.fetch.partition.stats=true;要想使用CBO引擎,必须构建数据的元数据【表行数、列的信息、分区的信息……】
提前获取这些信息,CBO才能基于代价选择合适的处理计划
所以CBO引擎一般搭配analyze分析优化器一起使用
Analyze分析优化器
用于提前运行一个MapReduce程序将表或者分区的信息构建一些元数据【表的信息、分区信息、列的信息】,搭配CBO引擎一起使用。
1
2
3
4
5
6
7
8
9
10
11
12-- 构建分区信息元数据
ANALYZE TABLE tablename
[PARTITION(partcol1[=val1], partcol2[=val2], ...)]
COMPUTE STATISTICS [noscan];
-- 构建列的元数据
ANALYZE TABLE tablename
[PARTITION(partcol1[=val1], partcol2[=val2], ...)]
COMPUTE STATISTICS FOR COLUMNS ( columns name1, columns name2...) [noscan];
-- 查看元数据
DESC FORMATTED [tablename] [columnname];
谓词下推(PPD)
谓词下推 Predicate Pushdown(PPD)的思想简单点说就是在不影响最终结果的情况下,尽量将过滤条件提前执行。谓词下推后,过滤条件在map端执行,减少了map端的输出,降低了数据在集群上传输的量,降低了Reduce端的数据负载,节约了集群的资源,也提升了任务的性能。
1 | -- 默认自动开启谓词下推 |

- Inner Join和Full outer Join,条件写在on后面,还是where后面,性能上面没有区别
- Left outer Join时 ,右侧的表写在on后面,左侧的表写在where后面,性能上有提高
- Right outer Join时,左侧的表写在on后面、右侧的表写在where后面,性能上有提高
- 如果SQL语句中出现不确定结果的函数,也无法实现下推
数据倾斜
group By的数据倾斜
当程序中出现group by或者count(distinct)等分组聚合的场景时,如果数据本身是倾斜的根据MapReduce的Hash分区规则,肯定会出现数据倾斜的现象。根本原因是因为分区规则导致的,所以我们可以通过以下几种方案来解决group by导致的数据倾斜的问题。
方案一:开启Map端聚合
1
2-- 开启Map端聚合:Combiner
hive.map.aggr=true;通过减少Reduce的输入量,避免每个Task数据差异过大导致数据倾斜
方案二:实现随机分区
1
2-- SQL中避免数据倾斜,构建随机分区
select * from table distribute by rand();distribute by用于指定底层的MapReduce按照哪个字段作为Key实现分区、分组等
默认由Hive自己选择,我们可以通过distribute by自己指定,通过rank函数随机值实现随机分区,避免数据倾斜
方案三:自动构建随机分区并自动聚合
1
2-- 开启随机分区,走两个MapReduce
hive.groupby.skewindata=true;开启该参数以后,当前程序会自动通过两个MapReduce来运行
第一个MapReduce自动进行随机分区,然后实现聚合
第二个MapReduce将聚合的结果再按照业务进行处理,得到结果
Join的数据倾斜
实际业务需求中往往需要构建两张表的Join实现,如果两张表比较大,无法实现Map Join,只能走Reduce Join,那么当关联字段中某一种值过多的时候依旧会导致数据倾斜的问题,面对Join产生的数据倾斜,我们核心的思想是尽量避免Reduce Join的产生,优先使用Map Join来实现,但往往很多的Join场景不满足Map Join的需求,那么我们可以以下几种方案来解决Join产生的数据倾斜问题:
方案一:提前过滤,将大数据变成小数据,实现Map Join
方案二:使用Bucket Join
方案三:使用Skew Join
Skew Join是Hive中一种专门为了避免数据倾斜而设计的特殊的Join过程,这种Join的原理是将Map Join和Reduce Join进行合并,如果某个值出现了数据倾斜,就会将产生数据倾斜的数据单独使用Map Join来实现,其他没有产生数据倾斜的数据由Reduce Join来实现,这样就避免了Reduce Join中产生数据倾斜的问题,最终将Map Join的结果和Reduce Join的结果进行Union合并
1
2
3
4
5
6
7
8
9
10-- 开启运行过程中skewjoin
set hive.optimize.skewjoin=true;
-- 如果这个key的出现的次数超过这个范围
set hive.skewjoin.key=100000;
-- 在编译时判断是否会产生数据倾斜
set hive.optimize.skewjoin.compiletime=true;
-- 不合并,提升性能
set hive.optimize.union.remove=true;
-- 如果Hive的底层走的是MapReduce,必须开启这个属性,才能实现不合并
set mapreduce.input.fileinputformat.input.dir.recursive=true;