本文为学习笔记,对应视频教程来自尚硅谷大数据Spark教程从入门到精通
Spark快速上手 创建Maven项目 增加Scala插件 Spark 由 Scala 语言开发的,我这里使用的 Scala 编译版本为 2.12.15。请通过官网查看 Spark 和 Scala 对应的版本关系Spark Documentation 。
WordCount 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package com.eitan.bigdata.spark.core.wordcountimport org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf , SparkContext }object Spark03_WordCount def main Array [String ]): Unit = { val sparkConf = new SparkConf ().setMaster("local" ).setAppName("WordCount" ) val sparkContext = new SparkContext (sparkConf) val lines: RDD [String ] = sparkContext.textFile("data\\1.txt,data\\2.txt" ) val words: RDD [String ] = lines.flatMap(_.split(" " )) val wordToOne: RDD [(String , Int )] = words.map( word => (word, 1 ) ) val wordToCount: RDD [(String , Int )] = wordToOne.reduceByKey(_ + _) val array: Array [(String , Int )] = wordToCount.collect() array.foreach(println) sparkContext.stop() } }
log4j.properties 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 log4j.rootCategory =ERROR, console log4j.appender.console =org.apache.log4j.ConsoleAppender log4j.appender.console.target =System.err log4j.appender.console.layout =org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern =%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n log4j.logger.org.apache.spark.repl.Main =ERROR log4j.logger.org.spark_project.jetty =ERROR log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle =ERROR log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper =ERROR log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter =ERROR log4j.logger.org.apache.parquet =ERROR log4j.logger.parquet =ERROR log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler =FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry =ERROR
为了不在控制台打印日志。
Spark运行环境 Local模式 所谓的 Local 模式,就是不需要其他任何节点资源就可以在本地执行 Spark 代码的环境,一般用于教学,调试,演示。
安装JDK 参考文章:Hadoop(一):集群搭建
下载压缩文件并解压 下载地址:https://spark.apache.org/downloads.html
1 2 3 # 通过 xftp 上传到指定文件夹下并解压 [root@CentOS7 software]# tar -zxf spark-3.2.1-bin-hadoop3.2.tgz -C /opt/module/ [eitan@SparkOrigin module]$ mv spark-3.2.1-bin-hadoop3.2/ spark-local-3.2.1
启动Local环境 1 [eitan@SparkOrigin module]$ ./spark-local-3.2.1/bin/spark-shell
WebUI监控页面:http://192.168.203.150:4040/
命令行工具 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). 22/05/20 16:59:20 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Spark context Web UI available at http://SparkOrigin:4040 Spark context available as 'sc' (master = local[*], app id = local-1653037162181). Spark session available as 'spark'. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ '_/ /___/ .__/\_,_/_/ /_/\_\ version 3.2.1 /_/ Using Scala version 2.12.15 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_212) Type in expressions to have them evaluated. Type :help for more information. scala> sc.textFile("spark-local-3.2.1/data/word.txt" ).flatMap(_.split(" " )).map((_,1)).reduceByKey(_+_).collect res0: Array[(String, Int)] = Array((Spark,1), (Hello,3), (World,1), (Scala,1))
提交应用 1 2 3 4 5 bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master local[2] \ ./examples/jars/spark-examples_2.12-3.2.1.jar \ 10
–class 表示要执行程序的主类,此处可以更换为咱们自己写的应用程序
–master local[2] 部署模式,默认为本地模式,数字表示分配的虚拟 CPU 核数量
spark-examples_2.12-3.0.0.jar 运行的应用类所在的 jar 包,实际使用时,可以设定为咱们自己打的 jar 包
数字 10 表示程序的入口参数,用于设定当前应用的任务数量
提交参数说明 1 2 3 4 5 6 bin/spark-submit \ --class <main-class> --master <master-url> \ ... # other options <application-jar> \ [application-arguments]
参数
解释
可选值举例
–class
Spark 程序中包含主函数的类
–master
Spark 程序运行的模式(环境)
模式:local[*]、spark://linux1:7077、Yarn
–executor-memory 1G
指定每个 executor 可用内存为 1G
符合集群内存配置即可,具体情况具体分析。
–total-executor-cores 2
指定所有executor使用的cpu核数为 2 个
–executor-cores
指定每个executor使用的cpu核数
application-jar
打包好的应用 jar,包含依赖。这个 URL 在集群中全局可见。
application-arguments
传给 main()方法的参数
Standalone模式 local 本地模式毕竟只是用来进行练习演示的,真实工作中还是要将应用提交到对应的集群中去执行,这里我们来看看只使用 Spark 自身节点运行的集群模式,也就是我们所谓的独立部署(Standalone)模式。Spark 的 Standalone 模式体现了经典的 master-slave 模式。
集群规划
spark151
spark152
spark153
Master Worker
Worker
解压缩文件 1 2 3 4 [eitan@spark151 ~]$ cd /opt/software/ [eitan@spark151 software]$ tar -zxf spark-3.2.1-bin-hadoop3.2.tgz -C /opt/module/ [eitan@spark151 software]$ cd /opt/module/ [eitan@spark151 module]$ mv spark-3.2.1-bin-hadoop3.2/ spark-standalone-3.2.1
修改配置文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # 1.进入解压缩后路径的 conf 目录,复制 workers.template 文件名为 workers [eitan@spark151 module]$ cd spark-standalone-3.2.1/conf/ [eitan@spark151 conf]$ cp workers.template workers # 2.修改 workers 文件,添加 worker 节点 [eitan@spark151 conf]$ vim workers # A Spark Worker will be started on each of the machines listed below. spark151 spark152 spark153 # 3.复制 spark-env.sh.template 文件名为 spark-env.sh [eitan@spark151 conf]$ cp spark-env.sh.template spark-env.sh # 4.修改 spark-env.sh 文件,添加 JAVA_HOME 环境变量和集群对应的 master 节点 export JAVA_HOME=/opt/module/jdk1.8.0_212 SPARK_MASTER_HOST=spark151 SPARK_MASTER_PORT=7077 # 5.分发 spark-standalone-3.2.1 目录 [eitan@spark151 ~]$ xsync /opt/module/spark-standalone-3.2.1/
启动集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # 1.执行脚本命令 [eitan@spark151 spark-standalone-3.2.1]$ ./sbin/start-all.sh # 2.查看三台服务器运行进程 [eitan@spark151 spark-standalone-3.2.1]$ xcall jps ================ spark151 ================ 8089 Worker 8014 Master 8142 Jps ================ spark152 ================ 7958 Worker 8007 Jps ================ spark153 ================ 7944 Worker 7993 Jps # 3.查看 Master 资源监控 Web UI 界面: http://192.168.203.151:8080/ # 4. 提交应用 bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://spark151:7077 \ ./examples/jars/spark-examples_2.12-3.2.1.jar \ 10
配置历史服务 首先要有Hadoop的集群环境,请参考Hadoop(一):集群搭建
hadoop配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 <configuration > <property > <name > fs.defaultFS</name > <value > hdfs://spark152:8020</value > </property > <property > <name > hadoop.tmp.dir</name > <value > /opt/module/hadoop-3.3.2/data</value > </property > <property > <name > hadoop.http.staticuser.user</name > <value > eitan</value > </property > </configuration > <configuration > <property > <name > dfs.namenode.http-address</name > <value > spark152:9870</value > </property > <property > <name > dfs.namenode.secondary.http-address</name > <value > spark153:9868</value > </property > </configuration >
1 2 3 4 [eitan@spark151 hadoop]$ cat workers spark151 spark152 spark153
spark配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 # 1.复制 spark-defaults.conf.template 文件名为 spark-defaults.conf [eitan@spark151 spark-standalone-3.2.1]$ cp conf/spark-defaults.conf.template conf/spark-defaults.conf # 2.修改 spark-default.conf 文件,配置日志存储路径 [eitan@spark151 spark-standalone-3.2.1]$ vim conf/spark-defaults.conf spark.eventLog.enabled true spark.eventLog.dir hdfs://spark152:8020/directory # 3.需要启动 hadoop 集群,HDFS 上的 directory 目录需要提前存在 [eitan@spark151 hadoop-3.3.2]$ ./sbin/start-dfs.sh [eitan@spark151 ~]$ hadoop fs -mkdir /directory # 4.修改 spark-env.sh 文件, 添加日志配置 [eitan@spark151 spark-standalone-3.2.1]$ vim conf/spark-env.sh export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://spark152:8020/directory -Dspark.history.retainedApplications=30" # 参数 1 含义:WEB UI 访问的端口号为 18080 # 参数 2 含义:指定历史服务器日志存储路径 # 参数 3 含义:指定保存 Application 历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数 # 5.重新启动集群和历史服务 [eitan@spark151 ~]$ xsync /opt/module/spark-standalone-3.2.1/conf/ # 6.重新启动集群和历史服务 [eitan@spark151 spark-standalone-3.2.1]$ ./sbin/start-all.sh # 7.重新执行任务 bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://spark151:7077 \ ./examples/jars/spark-examples_2.12-3.2.1.jar \ 10
Standalone配置高可用(HA) 集群规划
spark151
spark152
spark153
Master
Zookeeper
Master
解压安装Zookeeper 1 2 [eitan@spark151 software]$ tar -zxf apache-zookeeper-3.7.1-bin.tar.gz -C /opt/module/ [eitan@spark151 module]$ mv apache-zookeeper-3.7.1-bin/ apache-zookeeper-3.7.1/
配置Zookeeper 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 # 1.在/opt/module/apache-zookeeper-3.7.1/这个目录下创建 zkData [eitan@spark151 apache-zookeeper-3.7.1]$ mkdir zkData # 2.在/opt/module/apache-zookeeper-3.7.1/zkData 目录下创建一个 myid 的文件 [eitan@spark151 apache-zookeeper-3.7.1]$ vim zkData/myid # 在文件中添加与 server 对应的编号(注意:上下不要有空行,左右不要有空格) 1 # 3.拷贝配置好的 zookeeper 到其他机器上并分别在 spark152、spark153 上修改 myid 文件中内容为 2、3 [eitan@spark151 module]$ xsync apache-zookeeper-3.7.1/ # 4.复制/opt/module/apache-zookeeper-3.7.1/conf 这个目录下的 zoo_sample.cfg 为 zoo.cfg [eitan@spark151 apache-zookeeper-3.7.1]$ cp conf/zoo_sample.cfg conf/zoo.cfg # 5.修改 zoo.cfg 文件 # 修改 dataDir=/opt/module/apache-zookeeper-3.7.1/zkData # 新增 # cluster server.1=spark151:2888:3888 server.2=spark152:2888:3888 server.3=spark153:2888:3888 # 6.同步 zoo.cfg 配置文件 [eitan@spark151 apache-zookeeper-3.7.1]$ xsync conf/zoo.cfg
配置参数解读:
server.A=B:C:D
A 是一个数字,表示这个是第几号服务器。集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个server;B 是这个服务器的地址;C 是这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口;D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
Zookeeper集群启动停止脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 # 1.编写脚本 [eitan@spark151 ~]$ vim bin/zk.sh # !/bin/bash case $1 in "start"){ for host in spark151 spark152 spark153 do echo ---------- zookeeper $host 启动 ------------ ssh $host "/opt/module/apache-zookeeper-3.7.1/bin/zkServer.sh start" done };; "stop"){ for host in spark151 spark152 spark153 do echo ---------- zookeeper $host 停止 ------------ ssh $host "/opt/module/apache-zookeeper-3.7.1/bin/zkServer.sh stop" done };; "status"){ for host in spark151 spark152 spark153 do echo ---------- zookeeper $host 状态 ------------ ssh $host "/opt/module/apache-zookeeper-3.7.1/bin/zkServer.sh status" done };; esac # 2.增加脚本执行权限 [eitan@spark151 ~]$ chmod u+x bin/zk.sh # 3.通过脚本启动集群 [eitan@spark151 ~]$ zk.sh start # 4.通过脚本查看集群状态 [eitan@spark151 ~]$ zk.sh status ---------- zookeeper spark151 状态 ------------ ZooKeeper JMX enabled by default Using config: /opt/module/apache-zookeeper-3.7.1/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: follower ---------- zookeeper spark152 状态 ------------ ZooKeeper JMX enabled by default Using config: /opt/module/apache-zookeeper-3.7.1/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: leader ---------- zookeeper spark153 状态 ------------ ZooKeeper JMX enabled by default Using config: /opt/module/apache-zookeeper-3.7.1/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. Client SSL: false. Mode: follower
修改 spark-env.sh 文件添加如下配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 [eitan@spark151 ~]$ vim /opt/module/spark-standalone-3.2.1/conf/spark-env.sh # 注释以下内容 # SPARK_MASTER_HOST=spark151 # SPARK_MASTER_PORT=7077 # 添加如下内容 # Master 监控页面默认访问端口为 8080,但是可能会和 Zookeeper 冲突,所以改成 8989 SPARK_MASTER_WEBUI_PORT=8989 export SPARK_DAEMON_JAVA_OPTS=" -Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=spark151,spark152,spark153 -Dspark.deploy.zookeeper.dir=/spark" # 分发配置文件 [eitan@spark151 ~]$ xsync /opt/module/spark-standalone-3.2.1/conf/
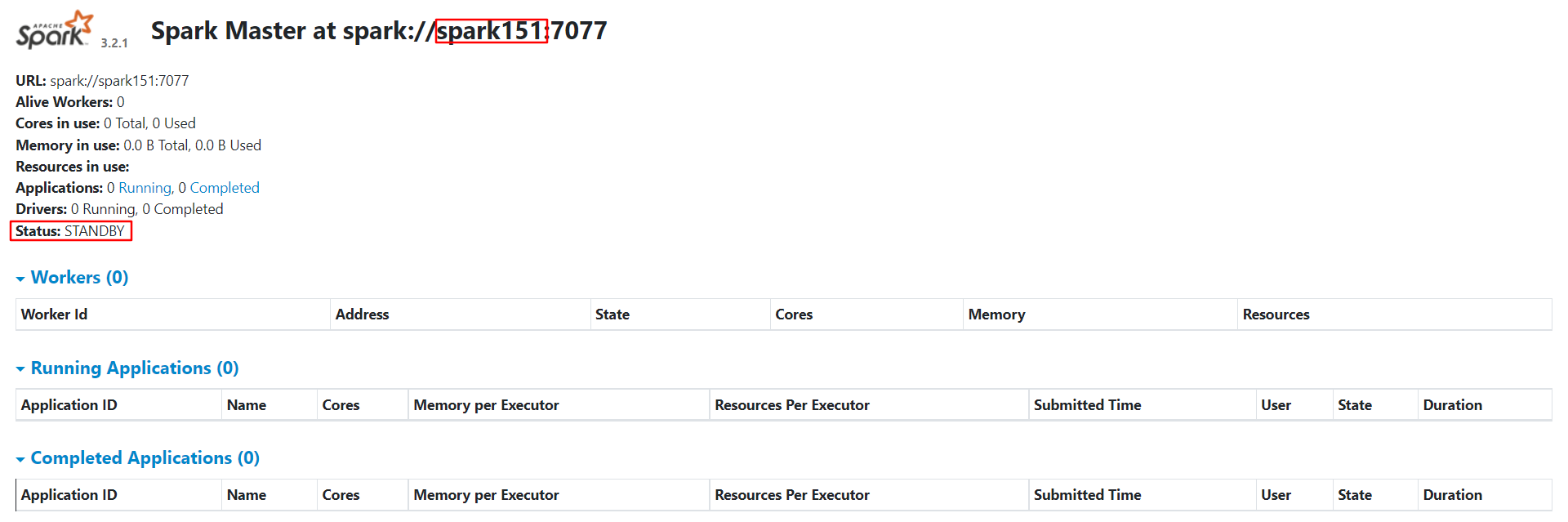
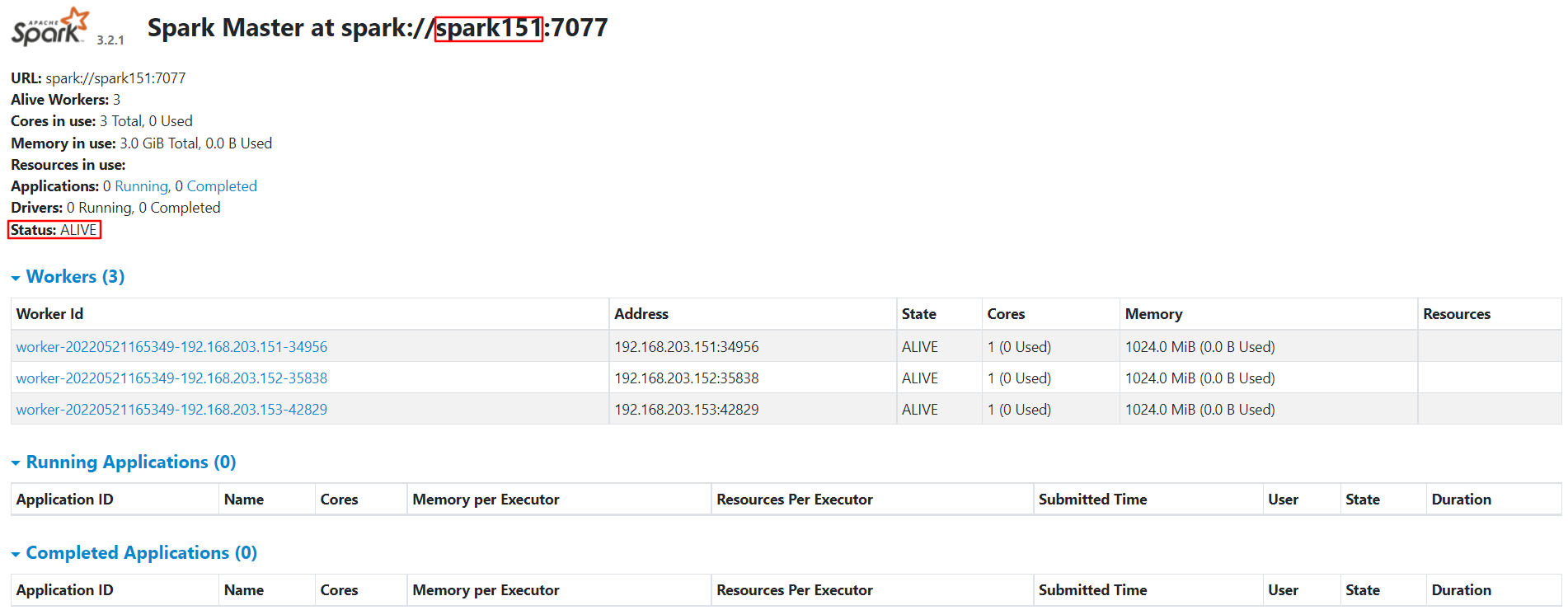
启动集群 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 # 1.在 spark152 上运行脚本启动集群 [eitan@spark152 apache-zookeeper-3.7.1]$ /opt/module/spark-standalone-3.2.1/sbin/start-all.sh # 2.发现 Master 在 spark152 上 [eitan@spark152 apache-zookeeper-3.7.1]$ xcall jps ================ spark151 ================ 20006 Worker 17798 DataNode 19752 QuorumPeerMain 20106 Jps ================ spark152 ================ 14306 Master 13443 NameNode 14499 Jps 14103 QuorumPeerMain 13531 DataNode 14399 Worker ================ spark153 ================ 14371 QuorumPeerMain 14709 Worker 14789 Jps 13560 SecondaryNameNode 13450 DataNode
在 spark151 上启动备用 Master 1 [eitan@spark151 ~]$ /opt/module/spark-standalone-3.2.1/sbin/start-master.sh
提交应用到高可用集群 1 2 3 4 5 bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master spark://spark151:7077,spark152:7077 \ ./examples/jars/spark-examples_2.12-3.2.1.jar \ 10
停止 spark152 的 Master 资源监控进程 1 2 3 4 5 6 7 8 [eitan@spark152 ~]$ jps 14306 Master 13443 NameNode 14644 Jps 14103 QuorumPeerMain 13531 DataNode 14399 Worker [eitan@spark152 ~]$ kill -9 14306
Spark-On-Yarn模式 独立部署(Standalone)模式由 Spark 自身提供计算资源,无需其他框架提供资源。这种方式降低了和其他第三方资源框架的耦合性,独立性非常强。但是你也要记住,Spark 主要是计算框架,而不是资源调度框架,所以本身提供的资源调度并不是它的强项,所以还是和其他专业的资源调度框架集成会更靠谱一些。
原理
SparkOnYarn 的本质是把 Spark 任务的 class 字节码文件打成 jar 包,上传到 Yarn 集群的 JVM 中运行;
Spark 集群的相关角色(Master,Worker)也会在 Yarn 的 JVM 中运行;
SparkOnYarn需要:
修改一些配置,使支持 SparkOnYarn
Spark 程序打成的 jar 包,如示例中的 jar 包 spark-examples_2.12-3.2.1.jar,也可以使用我们自己开发的程序达成的 jar 包
Spark 任务提交工具:bin/spark-submit
Spark 本身依赖的 jars:提交任务时会被上传到 Yarn/HDFS,可手动提前上传
SparkOnYarn 不需要 Spark 集群,只需要单机版 spark 即可;
SparkOnYarn 根据 Driver 运行在哪里分为两种模式:client 模式和 cluster 模式。
解压缩文件 1 2 3 [eitan@spark151 software]$ tar -zxf spark-3.2.1-bin-hadoop3.2.tgz -C /opt/module/ [eitan@spark151 software]$ cd /opt/module/ [eitan@spark151 module]$ mv spark-3.2.1-bin-hadoop3.2/ spark-yarn-3.2.1
配置yarn-site.xml 1 [eitan@spark151 module]$ vim hadoop-3.3.2/etc/hadoop/yarn-site.xml
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 <property > <name > yarn.resourcemanager.hostname</name > <value > spark151</value > </property > <property > <name > yarn.nodemanager.aux-services</name > <value > mapreduce_shuffle</value > </property > <property > <name > yarn.nodemanager.resource.memory-mb</name > <value > 20480</value > </property > <property > <name > yarn.scheduler.minimum-allocation-mb</name > <value > 2048</value > </property > <property > <name > yarn.nodemanager.vmem-pmem-ratio</name > <value > 2.1</value > </property > <property > <name > yarn.log-aggregation-enable</name > <value > true</value > </property > <property > <name > yarn.log-aggregation.retain-seconds</name > <value > 604800</value > </property > <property > <name > yarn.log.server.url</name > <value > http://spark153:19888/jobhistory/logs</value > </property > <property > <name > yarn.nodemanager.pmem-check-enabled</name > <value > false</value > </property > <property > <name > yarn.nodemanager.vmem-check-enabled</name > <value > false</value > </property >
1 2 # 分发给其他节点 [eitan@spark151 module]$ xsync hadoop-3.3.2/etc/hadoop/yarn-site.xml
配置Spark的历史服务器和Yarn的整合 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 # 1.修改spark-defaults.conf [eitan@spark151 module]$ cp .conf/spark-defaults.conf.template ./conf/spark-defaults.conf [eitan@spark151 spark-yarn-3.2.1]$ vim conf/spark-defaults.conf spark.eventLog.enabled true spark.eventLog.dir hdfs://spark152:8020/directory spark.yarn.historyServer.address spark151:18080 spark.history.ui.port 18080 # 2.修改spark-env.sh [eitan@spark151 spark-yarn-3.2.1]$ cp conf/spark-env.sh.template conf/spark-env.sh # spark-standalone export JAVA_HOME=/opt/module/jdk1.8.0_212 YARN_CONF_DIR=/opt/module/hadoop-3.3.2/etc/hadoop # history-server export SPARK_HISTORY_OPTS=" -Dspark.history.ui.port=18080 -Dspark.history.fs.logDirectory=hdfs://spark152:8020/directory -Dspark.history.retainedApplications=30"
修改日志级别 1 2 3 4 5 [eitan@spark151 spark-yarn-3.2.1]$ cp conf/log4j.properties.template conf/log4j.properties [eitan@spark151 spark-yarn-3.2.1]$ vim conf/log4j.properties # 修改日志级别为 WARN # Set everything to be logged to the console log4j.rootCategory=WARN, console
配置依赖的 Spark 的jar包 1 2 3 4 5 6 7 8 9 10 # 1.在HDFS上创建存储spark相关jar包的目录 [eitan@spark151 ~]$ hadoop fs -mkdir -p /spark/jars # 2.上传$SPARK_HOME /jars所有jar包到HDFS [eitan@spark151 ~]$ hadoop fs -put /opt/module/spark-yarn-3.2.1/jars/* /spark/jars # 3.修改spark-defaults.conf [eitan@spark151 spark-yarn-3.2.1]$ vim conf/spark-defaults.conf # 预上传所需要的jar包 spark.yarn.jars hdfs://spark152:8020/spark/jars/*
启动服务 1 2 [eitan@spark151 ~]$ /opt/module/hadoop-3.3.2/sbin/start-dfs.sh [eitan@spark151 ~]$ /opt/module/hadoop-3.3.2/sbin/start-yarn.sh
提交应用 1 2 3 4 5 6 bin/spark-submit \ --class org.apache.spark.examples.SparkPi \ --master yarn \ --deploy-mode cluster \ ./examples/jars/spark-examples_2.12-3.2.1.jar \ 10
进入 http://192.168.203.151:8088/ 后无法点入每个 Application 的 History
启动 Spark 的历史服务器 1 [eitan@spark151 spark-yarn-3.2.1]$ sbin/start-history-server.sh
开启 Spark 的历史服务器,可以进入每个 Application 的 History,但是却看不了对应任务的 stdout 和 stderr
配置 MapReduce 的历史服务器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [eitan@spark151 hadoop-3.3.2]$ vim ./etc/hadoop/mapred-site.xml <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>spark153:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>spark153:19888</value> </property>
重启所有服务 1 2 3 4 [eitan@spark151 module]$ ./hadoop-3.3.2/sbin/start-dfs.sh [eitan@spark151 module]$ ./hadoop-3.3.2/sbin/start-yarn.sh [eitan@spark151 module]$ ./spark-yarn-3.2.1/sbin/start-history-server.sh [eitan@spark153 ~]$ mapred --daemon start historyserver
所有功能均可正常使用
部署模式对比
模式
Spark 安装机器数
需启动的进程
所属者
应用场景
Local
1
无
Spark
测试
Standalone
3
Master及Worker
Spark
单独部署
Yarn
1
Yarn及HDFS
Hadoop
混合部署
端口号
Spark 查看当前 Spark-shell 运行任务情况端口号:4040(计算)
Spark Master 内部通信服务端口号:7077
Standalone 模式下,Spark Master Web 端口号:8080(资源)
Spark 历史服务器端口号:18080
Hadoop YARN 任务运行情况查看端口号:8088