/** * Internally, each RDD is characterized by five main properties: * * - A list of partitions * - A function for computing each split * - A list of dependencies on other RDDs * - Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned) * - Optionally, a list of preferred locations to compute each split on (e.g. block locations for * an HDFS file) */
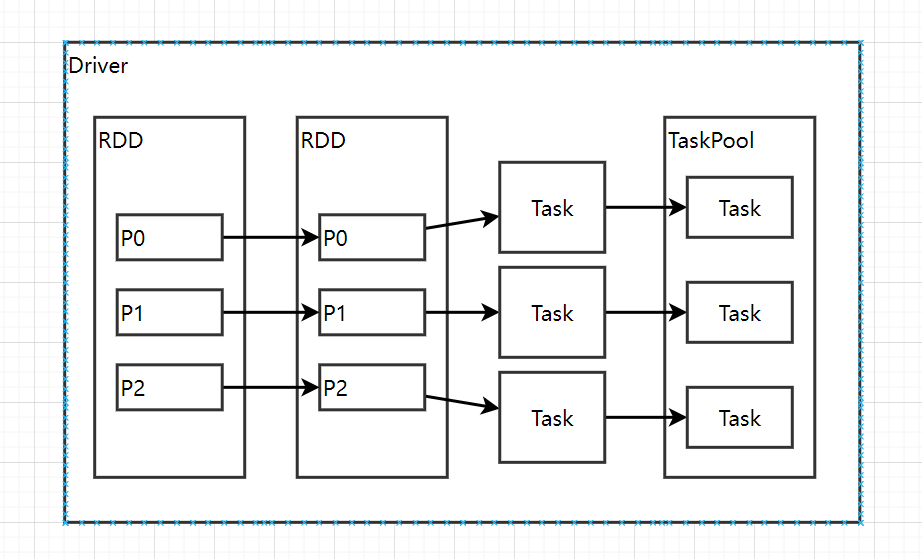
分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
1 2 3 4 5 6 7 8
/** * Implemented by subclasses to return the set of partitions in this RDD. This method will only * be called once, so it is safe to implement a time-consuming computation in it. * * The partitions in this array must satisfy the following property: * `rdd.partitions.zipWithIndex.forall { case (partition, index) => partition.index == index }` */ protecteddefgetPartitions: Array[Partition]
分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算
1 2 3 4 5 6
/** * :: DeveloperApi :: * Implemented by subclasses to compute a given partition. */ @DeveloperApi defcompute(split: Partition, context: TaskContext): Iterator[T]
RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系
1 2 3 4 5
/** * Implemented by subclasses to return how this RDD depends on parent RDDs. This method will only * be called once, so it is safe to implement a time-consuming computation in it. */ protecteddefgetDependencies: Seq[Dependency[_]] = deps
分区器(可选)
当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区
1 2
/** Optionally overridden by subclasses to specify how they are partitioned. */ @transientval partitioner: Option[Partitioner] = None
首选位置(可选)
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算
1 2 3 4
/** * Optionally overridden by subclasses to specify placement preferences. */ protecteddefgetPreferredLocations(split: Partition): Seq[String] = Nil
objectSpark02_RDD_File{ defmain(args: Array[String]): Unit = { // TODO 准备环境 val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("RDD") val sparkContext = newSparkContext(sparkConf)
// TODO 创建RDD // 本地文件 val localRdd: RDD[String] = sparkContext.textFile("data/1.txt") // 分布式文件 val hdfsRdd: RDD[String] = sparkContext.textFile("hdfs://spark152:8020/data/1.txt") // textFile:以行为单位读取数据 // wholeTextFiles:以文件为单位读取数据 val wholeTextRdd: RDD[(String, String)] = sparkContext.wholeTextFiles("hdfs://spark152:8020/data")
// Sequences need to be sliced at the same set of index positions for operations // like RDD.zip() to behave as expected defpositions(length: Long, numSlices: Int): Iterator[(Int, Int)] = { (0 until numSlices).iterator.map { i => val start = ((i * length) / numSlices).toInt val end = (((i + 1) * length) / numSlices).toInt (start, end) } }
overridedefslice(from: Int, until: Int): Array[T] = { val reprVal = repr val lo = math.max(from, 0) val hi = math.min(math.max(until, 0), reprVal.length) val size = math.max(hi - lo, 0) val result = java.lang.reflect.Array.newInstance(elementClass, size) if (size > 0) { Array.copy(reprVal, lo, result, 0, size) } result.asInstanceOf[Array[T]] }
public InputSplit[] getSplits(JobConf job, int numSplits) throws IOException { StopWatch sw = new StopWatch().start(); FileStatus[] stats = listStatus(job);
// Save the number of input files for metrics/loadgen job.setLong(NUM_INPUT_FILES, stats.length); long totalSize = 0; // compute total size boolean ignoreDirs = !job.getBoolean(INPUT_DIR_RECURSIVE, false) && job.getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false);
List<FileStatus> files = new ArrayList<>(stats.length); for (FileStatus file: stats) { // check we have valid files if (file.isDirectory()) { if (!ignoreDirs) { thrownew IOException("Not a file: "+ file.getPath()); } } else { files.add(file); totalSize += file.getLen(); } }
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits); long minSize = Math.max(job.getLong(org.apache.hadoop.mapreduce.lib.input. FileInputFormat.SPLIT_MINSIZE, 1), minSplitSize);
// generate splits ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits); NetworkTopology clusterMap = new NetworkTopology(); for (FileStatus file: files) { Path path = file.getPath(); long length = file.getLen(); if (length != 0) { FileSystem fs = path.getFileSystem(job); BlockLocation[] blkLocations; if (file instanceof LocatedFileStatus) { blkLocations = ((LocatedFileStatus) file).getBlockLocations(); } else { blkLocations = fs.getFileBlockLocations(file, 0, length); } if (isSplitable(fs, path)) { long blockSize = file.getBlockSize(); long splitSize = computeSplitSize(goalSize, minSize, blockSize);
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[String] = sparkContext.textFile("data/apache.log")
val mapRdd: RDD[String] = rdd.map( line => { val array: Array[String] = line.split(" ") array(6) } )
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4),2)
val mapPartitionsRdd: RDD[Int] = rdd.mapPartitions( iterator => List(iterator.max).iterator )
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 2)
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[String] = sparkContext.makeRDD(List("Hello World", "Hello Spark"))
val flatMapRdd: RDD[String] = rdd.flatMap(_.split(" "))
def main(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 2)
val glomRdd: RDD[Array[Int]] = rdd.glom() val mapRdd: RDD[Int] = glomRdd.map(_.max)
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[String] = sparkContext.makeRDD(List("Hello", "hive", "hbase", "Hadoop"))
val groupRdd: RDD[(Char, Iterable[String])] = rdd.groupBy(_.charAt(0))
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[String] = sparkContext.textFile("data/apache.log")
val filterRdd: RDD[String] = rdd.filter( line => { line.split(" ")(3).startsWith("17/05/2015") } )
/** * Return a sampled subset of this RDD. * * @param withReplacement can elements be sampled multiple times (replaced when sampled out) * @param fraction expected size of the sample as a fraction of this RDD's size * without replacement: probability that each element is chosen; fraction must be [0, 1] * with replacement: expected number of times each element is chosen; fraction must be greater * than or equal to 0 * @param seed seed for the random number generator * * @note This is NOT guaranteed to provide exactly the fraction of the count * of the given [[RDD]]. */ defsample( withReplacement: Boolean, fraction: Double, seed: Long = Utils.random.nextLong)
distinct
1 2 3 4 5 6 7 8 9 10 11 12 13 14
objectSpark09_RDD_Operator_Transform_Distinct{
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
/** * Return a new RDD that is reduced into `numPartitions` partitions. * * This results in a narrow dependency, e.g. if you go from 1000 partitions * to 100 partitions, there will not be a shuffle, instead each of the 100 * new partitions will claim 10 of the current partitions. If a larger number * of partitions is requested, it will stay at the current number of partitions. * * However, if you're doing a drastic coalesce, e.g. to numPartitions = 1, * this may result in your computation taking place on fewer nodes than * you like (e.g. one node in the case of numPartitions = 1). To avoid this, * you can pass shuffle = true. This will add a shuffle step, but means the * current upstream partitions will be executed in parallel (per whatever * the current partitioning is). * * @note With shuffle = true, you can actually coalesce to a larger number * of partitions. This is useful if you have a small number of partitions, * say 100, potentially with a few partitions being abnormally large. Calling * coalesce(1000, shuffle = true) will result in 1000 partitions with the * data distributed using a hash partitioner. The optional partition coalescer * passed in must be serializable. */ defcoalesce(numPartitions: Int, shuffle: Boolean = false, partitionCoalescer: Option[PartitionCoalescer] = Option.empty) (implicit ord: Ordering[T] = null)
/** * Return a new RDD that has exactly numPartitions partitions. * * Can increase or decrease the level of parallelism in this RDD. Internally, this uses * a shuffle to redistribute data. * * If you are decreasing the number of partitions in this RDD, consider using `coalesce`, * which can avoid performing a shuffle. */ defrepartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope { coalesce(numPartitions, shuffle = true) }
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
val rdd1: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4)) val rdd2: RDD[Int] = sparkContext.makeRDD(List(3, 4, 5, 6))
// zip 拉链:将两个 RDD 中的元素,以键值对的形式进行合并。 println(rdd1.zip(rdd2).collect().mkString(",")) sparkContext.stop() } }
Key - Value 类型
partitionBy
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
objectSpark12_RDD_Operator_Transform_PartitionBy{
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 4)
/** * 将数据按照相同的 Key 对 Value 进行聚合 */ objectSpark13_RDD_Operator_Transform_ReduceByKey{
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
/** * 将数据按照相同的 Key 对 Value 进行聚合 */ objectSpark14_RDD_Operator_Transform_GroupByKey{
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
/** * 需求:求不同 Key 的 Value 平均值 */ objectSpark15_RDD_Operator_Transform_AggregateByKey_Average{
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Operator") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[String] = sparkContext.textFile("data/agent.log") rdd.map( line => { val data: Array[String] = line.split(" ") ((data(1), data(4)), 1) } ).reduceByKey(_ + _) .map( data => { (data._1._1, (data._1._2, data._2)) } ).groupByKey() .mapValues( _.toList.sortBy(_._2)(Ordering.Int.reverse).take(3) ).collect().foreach(println)
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Serial") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[String] = sparkContext.makeRDD(Array("hello world", "hello spark", "hive", "atguigu"))
/** * ---------------- lines ---------------- * (2) data\1.txt,data\2.txt MapPartitionsRDD[1] at textFile at Spark01_RDD_Dependence.scala:11 [] * | data\1.txt,data\2.txt HadoopRDD[0] at textFile at Spark01_RDD_Dependence.scala:11 [] * ---------------- words ---------------- * (2) MapPartitionsRDD[2] at flatMap at Spark01_RDD_Dependence.scala:15 [] * | data\1.txt,data\2.txt MapPartitionsRDD[1] at textFile at Spark01_RDD_Dependence.scala:11 [] * | data\1.txt,data\2.txt HadoopRDD[0] at textFile at Spark01_RDD_Dependence.scala:11 [] * ---------------- wordToOne ---------------- * (2) MapPartitionsRDD[3] at map at Spark01_RDD_Dependence.scala:19 [] * | MapPartitionsRDD[2] at flatMap at Spark01_RDD_Dependence.scala:15 [] * | data\1.txt,data\2.txt MapPartitionsRDD[1] at textFile at Spark01_RDD_Dependence.scala:11 [] * | data\1.txt,data\2.txt HadoopRDD[0] at textFile at Spark01_RDD_Dependence.scala:11 [] * ---------------- wordToSum ---------------- * (2) ShuffledRDD[4] at reduceByKey at Spark01_RDD_Dependence.scala:23 [] * +-(2) MapPartitionsRDD[3] at map at Spark01_RDD_Dependence.scala:19 [] * | MapPartitionsRDD[2] at flatMap at Spark01_RDD_Dependence.scala:15 [] * | data\1.txt,data\2.txt MapPartitionsRDD[1] at textFile at Spark01_RDD_Dependence.scala:11 [] * | data\1.txt,data\2.txt HadoopRDD[0] at textFile at Spark01_RDD_Dependence.scala:11 [] * (Hello,4) * (World,2) * (Spark,2) */ objectSpark01_RDD_Dependence{ defmain(args: Array[String]): Unit = { val sparkConf = newSparkConf().setMaster("local").setAppName("Dependence") val sparkContext = newSparkContext(sparkConf)
val lines: RDD[String] = sparkContext.textFile("data\\1.txt,data\\2.txt") println("---------------- lines ----------------") println(lines.toDebugString)
val words: RDD[String] = lines.flatMap(_.split(" ")) println("---------------- words ----------------") println(words.toDebugString)
/** * :: DeveloperApi :: * Represents a dependency on the output of a shuffle stage. Note that in the case of shuffle, * the RDD is transient since we don't need it on the executor side. * * @param _rdd the parent RDD * @param partitioner partitioner used to partition the shuffle output * @param serializer [[org.apache.spark.serializer.Serializer Serializer]] to use. If not set * explicitly then the default serializer, as specified by `spark.serializer` * config option, will be used. * @param keyOrdering key ordering for RDD's shuffles * @param aggregator map/reduce-side aggregator for RDD's shuffle * @param mapSideCombine whether to perform partial aggregation (also known as map-side combine) * @param shuffleWriterProcessor the processor to control the write behavior in ShuffleMapTask */ classShuffleDependency[K: ClassTag, V: ClassTag, C: ClassTag]( @transient private val _rdd: RDD[_ <: Product2[K, V]], val partitioner: Partitioner, val serializer: Serializer = SparkEnv.get.serializer, val keyOrdering: Option[Ordering[K]] = None, val aggregator: Option[Aggregator[K, V, C]] = None, val mapSideCombine: Boolean = false, val shuffleWriterProcessor: ShuffleWriteProcessor = new ShuffleWriteProcessor) extendsDependency[Product2[K, V]] withLogging
/** * Create a ResultStage associated with the provided jobId. */ privatedefcreateResultStage( rdd: RDD[_], func: (TaskContext, Iterator[_]) => _, partitions: Array[Int], jobId: Int, callSite: CallSite): ResultStage = { val (shuffleDeps, resourceProfiles) = getShuffleDependenciesAndResourceProfiles(rdd) val resourceProfile = mergeResourceProfilesForStage(resourceProfiles) checkBarrierStageWithDynamicAllocation(rdd) checkBarrierStageWithNumSlots(rdd, resourceProfile) checkBarrierStageWithRDDChainPattern(rdd, partitions.toSet.size) val parents = getOrCreateParentStages(shuffleDeps, jobId) val id = nextStageId.getAndIncrement() val stage = newResultStage(id, rdd, func, partitions, parents, jobId, callSite, resourceProfile.id) stageIdToStage(id) = stage updateJobIdStageIdMaps(jobId, stage) stage }
/** * Get or create the list of parent stages for the given shuffle dependencies. The new * Stages will be created with the provided firstJobId. */ privatedefgetOrCreateParentStages(shuffleDeps: HashSet[ShuffleDependency[_, _, _]], firstJobId: Int): List[Stage] = { shuffleDeps.map { shuffleDep => getOrCreateShuffleMapStage(shuffleDep, firstJobId) }.toList }
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Cache") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[String] = sparkContext.makeRDD(Array("Hello World", "Hello Spark"))
val flatMapRdd: RDD[String] = rdd.flatMap(_.split(" "))
val mapRdd: RDD[(String, Int)] = flatMapRdd.map( word => { println("------ map ------") (word, 1) } )
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Persist") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[String] = sparkContext.makeRDD(Array("Hello World", "Hello Spark"))
val flatMapRdd: RDD[String] = rdd.flatMap(_.split(" "))
val mapRdd: RDD[(String, Int)] = flatMapRdd.map( word => { println("------ map ------") (word, 1) } )
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("CheckPoint") val sparkContext = newSparkContext(sparkConf) sparkContext.setCheckpointDir("checkpoint")
val rdd: RDD[String] = sparkContext.makeRDD(Array("Hello World", "Hello Spark"))
val flatMapRdd: RDD[String] = rdd.flatMap(_.split(" "))
val mapRdd: RDD[(String, Int)] = flatMapRdd.map( word => { println("------ map ------") (word, 1) } )
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Partitioner") val sparkContext = newSparkContext(sparkConf)
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Accumulator") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4))
// 获取系统累加器 val sumAcc: LongAccumulator = sparkContext.longAccumulator("sum")
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Accumulator") val sparkContext = newSparkContext(sparkConf)
val rdd: RDD[String] = sparkContext.makeRDD(List("Hello Spark", "Hello World", "Hello Scala"))
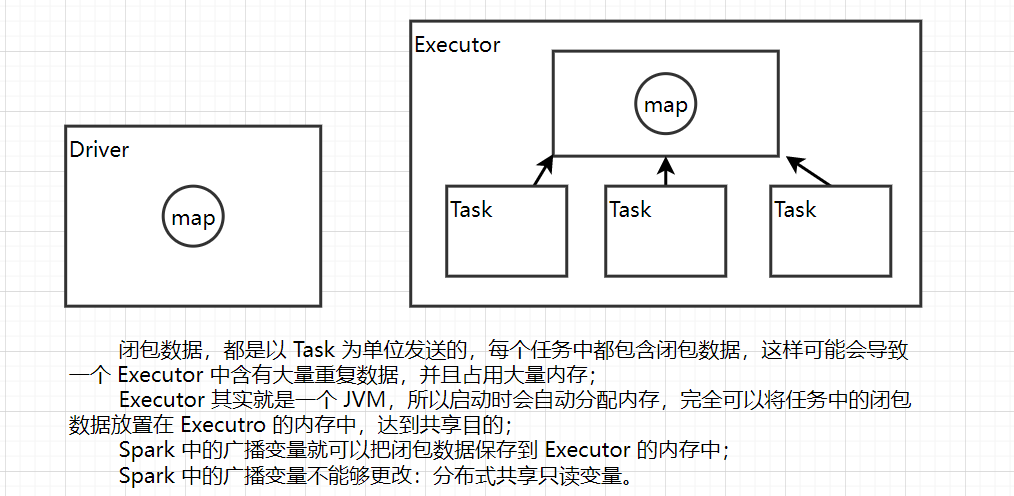
defmain(args: Array[String]): Unit = { val sparkConf: SparkConf = newSparkConf().setMaster("local[*]").setAppName("Broadcast") val sparkContext = newSparkContext(sparkConf)
objectSpark01_HotCategoryTop10{ defmain(args: Array[String]): Unit = { val sparkConf = newSparkConf().setMaster("local[*]").setAppName("Case") val sparkContext = newSparkContext(sparkConf)
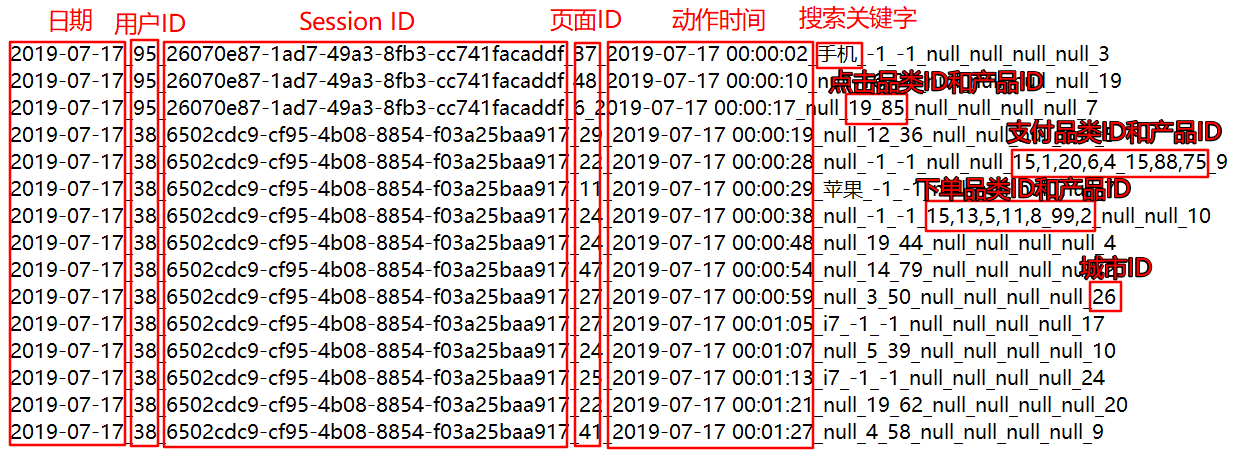
// 1. 读取原始日志数据 val actionRDD: RDD[String] = sparkContext.textFile("data\\user_visit_action.txt")
// 2. 统计品类的点击数量:(品类ID,点击数量) val clickActionRdd: RDD[String] = actionRDD.filter(_.split("_")(6) != "-1")
val clickCountRdd: RDD[(String, Int)] = clickActionRdd.map( action => { val datas: Array[String] = action.split("_") (datas(6), 1) } ).reduceByKey(_ + _)
// 3. 统计品类的下单数量:(品类ID,下单数量) val orderActionRdd: RDD[String] = actionRDD.filter(_.split("_")(8) != "null")
val orderCountRdd: RDD[(String, Int)] = orderActionRdd.flatMap( action => { val datas: Array[String] = action.split("_") val cidStr: String = datas(8) val cids: Array[String] = cidStr.split(",") cids.map((_, 1)) } ).reduceByKey(_ + _)
// 4. 统计品类的支付数量:(品类ID,支付数量) val payActionRdd: RDD[String] = actionRDD.filter(_.split("_")(10) != "null")
val payCountRdd: RDD[(String, Int)] = payActionRdd.flatMap( action => { val datas: Array[String] = action.split("_") val cidStr: String = datas(10) val cids: Array[String] = cidStr.split(",") cids.map((_, 1)) } ).reduceByKey(_ + _)
cogroupRdd.mapValues { case (clickIter, orderIter, payIter) => { val clickCount: Int = if (clickIter.iterator.hasNext) clickIter.iterator.next() else0 val orderCount: Int = if (orderIter.iterator.hasNext) orderIter.iterator.next() else0 val payCount: Int = if (payIter.iterator.hasNext) payIter.iterator.next() else0 (clickCount, orderCount, payCount) } }.sortBy(_._2, false).take(10).foreach(println)
objectSpark02_HotCategoryTop10{ defmain(args: Array[String]): Unit = { val sparkConf = newSparkConf().setMaster("local[*]").setAppName("Case") val sparkContext = newSparkContext(sparkConf)
// 1. 读取原始日志数据 val actionRDD: RDD[String] = sparkContext.textFile("data\\user_visit_action.txt") actionRDD.cache()
// 2. 统计品类的点击数量:(品类ID,点击数量) val clickActionRdd: RDD[String] = actionRDD.filter(_.split("_")(6) != "-1")
val clickCountRdd: RDD[(String, Int)] = clickActionRdd.map( action => { val datas: Array[String] = action.split("_") (datas(6), 1) } ).reduceByKey(_ + _)
// 3. 统计品类的下单数量:(品类ID,下单数量) val orderActionRdd: RDD[String] = actionRDD.filter(_.split("_")(8) != "null")
val orderCountRdd: RDD[(String, Int)] = orderActionRdd.flatMap( action => { val datas: Array[String] = action.split("_") val cidStr: String = datas(8) val cids: Array[String] = cidStr.split(",") cids.map((_, 1)) } ).reduceByKey(_ + _)
// 4. 统计品类的支付数量:(品类ID,支付数量) val payActionRdd: RDD[String] = actionRDD.filter(_.split("_")(10) != "null")
val payCountRdd: RDD[(String, Int)] = payActionRdd.flatMap( action => { val datas: Array[String] = action.split("_") val cidStr: String = datas(10) val cids: Array[String] = cidStr.split(",") cids.map((_, 1)) } ).reduceByKey(_ + _)
objectSpark03_HotCategoryTop10{ defmain(args: Array[String]): Unit = { val sparkConf = newSparkConf().setMaster("local[*]").setAppName("Case") val sparkContext = newSparkContext(sparkConf)
// 1. 读取原始日志数据 val actionRDD: RDD[String] = sparkContext.textFile("data\\user_visit_action.txt")
objectSpark04_HotCategoryTop10{ defmain(args: Array[String]): Unit = { val sparkConf = newSparkConf().setMaster("local[*]").setAppName("Case") val sparkContext = newSparkContext(sparkConf)
// 1. 读取原始日志数据 val actionRDD: RDD[String] = sparkContext.textFile("data\\user_visit_action.txt")
// 2. 声明累加器 val accumulator = newHotCategoryAccumulator sparkContext.register(accumulator, "hotCategoryAccumulator")
objectSpark05_HotCategoryAndSessionTop10{ defmain(args: Array[String]): Unit = { val sparkConf = newSparkConf().setMaster("local[*]").setAppName("Case") val sparkContext = newSparkContext(sparkConf)
// 1.读取原始日志数据 val actionRDD: RDD[String] = sparkContext.textFile("data\\user_visit_action.txt") actionRDD.cache()
// 2. 获取热门品类Top10的ID val ids: Array[String] = hotCategoryIDsTop10(actionRDD)
// 3.过滤原始数据保留前10品类的点击数据 val filterActionRdd: RDD[String] = actionRDD.filter( line => { val data: Array[String] = line.split("_") ids.contains(data(6)) } )
// 4.根据品类ID和session进行点击量统计 val reduceRdd: RDD[((String, String), Int)] = filterActionRdd.map( line => { val data: Array[String] = line.split("_") ((data(6), data(2)), 1) } ).reduceByKey(_ + _)
defmain(args: Array[String]): Unit = { val sparkConf = newSparkConf().setMaster("local[*]").setAppName("Case") val sparkContext = newSparkContext(sparkConf)
val actionRDD: RDD[String] = sparkContext.textFile("data\\user_visit_action.txt")
val actionDataRdd: RDD[UserVisitAction] = actionRDD.map( castToUserVisitAction(_) ) actionDataRdd.cache()
// TODO 对指定页面连续跳转进行统计 // 1-2,2-3,3-4,4-5,5-6,6-7 val ids: List[Long] = List[Long](1, 2, 3, 4, 5, 6, 7) val wantFlowIds: List[(Long, Long)] = ids.zip(ids.tail)