本文为学习笔记,对应视频教程来自尚硅谷大数据Spark教程从入门到精通
SparkSQL 概述 SparkSQL 是什么 Spark SQL 是 Spark 用于结构化数据(structured data)处理的 Spark 模块。
SparkSQL 特点
无缝的整合了 SQL 查询和 Spark 编程
统一的数据访问
兼容 Hive
标准数据连接
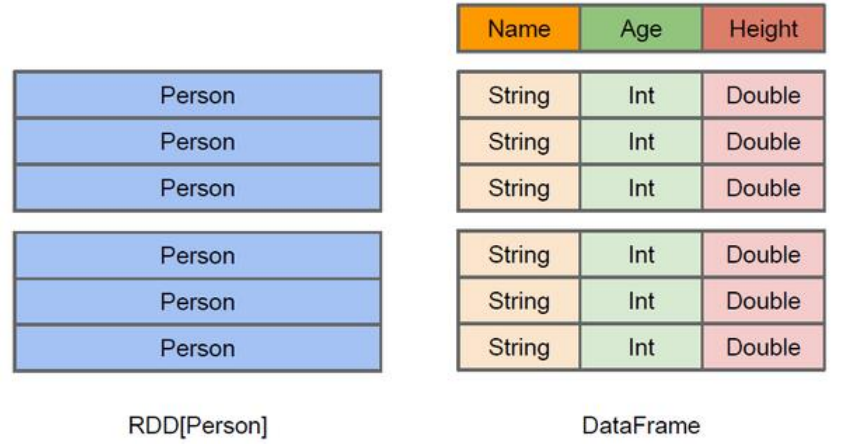
DataFrame 是什么 在 Spark 中,DataFrame 是一种以 RDD 为基础的分布式数据集,类似于传统数据库中的二维表格。DataFrame 与 RDD 的主要区别在于,前者带有 schema 元信息,即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型。这使得 Spark SQL 得以洞察更多的结构信息,从而对藏于 DataFrame 背后的数据源以及作用于 DataFrame 之上的变换进行了针对性的优化,最终达到大幅提升运行时效率的目标。反观 RDD,由于无从得知所存数据元素的具体内部结构,Spark Core 只能在 stage 层面进行简单、通用的流水线优化。
DataFrame 是为数据提供了 Schema 的视图。可以把它当做数据库中的一张表来对待DataFrame 也是懒执行的,但性能上比 RDD 要高,主要原因:优化的执行计划,即查询计划通过 Spark catalyst optimiser 进行优化。
DataSet 是什么 DataSet 是分布式数据集合。DataSet 是 Spark 1.6 中添加的一个新抽象,是 DataFrame 的一个扩展。它提供了 RDD 的优势(强类型,使用强大的 lambda 函数的能力)以及 Spark SQL 优化执行引擎的优点。DataSet 也可以使用功能性的转换(操作 map,flatMap,filter 等等)。
DataSet 是 DataFrame API 的一个扩展,是 SparkSQL 最新的数据抽象;
用户友好的 API 风格,既具有类型安全检查也具有 DataFrame 的查询优化特性;
用样例类来对 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到 DataSet 中的字段名称;
DataSet 是强类型的。比如可以有 DataSet[Car],DataSet[Person];
DataFrame 是 DataSet 的特列,DataFrame=DataSet[Row] ,所以可以通过 as 方法将 DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些的类型一样,所有的表结构信息都用 Row 来表示。获取数据时需要指定顺序
SparkSQL 核心编程 DataFrame 创建 DataFrame 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 # 在 spark 的 bin/input 目录中创建 user.json 文件 [eitan@SparkOrigin ~]$ vim /opt/module/spark-local-3.2.1/bin/input/user.json {"username":"zhangsan", "age":30} {"username":"lisi", "age":20} {"username":"wangwu", "age":40} # 查看 Spark 支持创建文件的数据源格式 scala> spark.read. csv format jdbc json load option options orc parquet schema table text textFile # 读取 json 文件创建 DataFrame scala> val df = spark.read.json("/opt/module/spark-local-3.2.1/bin/input/user.json" ) df: org.apache.spark.sql.DataFrame = [age: bigint, username: string] # 查看数据 scala> df.show +---+--------+ |age|username| +---+--------+ | 30|zhangsan| | 20| lisi| | 40| wangwu| +---+--------+ # 对于 DataFrame 创建一个全局表 scala> df.createOrReplaceGlobalTempView("people" ) # 通过 SQL 语句实现查询全表 scala> spark.newSession.sql("SELECT * FROM global_temp.people" ).show +---+--------+ |age|username| +---+--------+ | 30|zhangsan| | 20| lisi| | 40| wangwu| +---+--------+
SQL 语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 # 读取 JSON 文件创建 DataFrame scala> var df = spark.read.json("bin/input/user.json" ) df: org.apache.spark.sql.DataFrame = [age: bigint, username: string] # 对 DataFrame 创建一个临时表 scala> df.createOrReplaceTempView("people" ) # 通过 SQL 语句实现查询全表 scala> var sqlDF = spark.sql("SELECT * FROM people" ) sqlDF: org.apache.spark.sql.DataFrame = [age: bigint, username: string] # 结果展示 scala> sqlDF.show +---+--------+ |age|username| +---+--------+ | 30|zhangsan| | 20| lisi| | 40| wangwu| +---+--------+
DSL 语法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 # 查看 DataFrame 的 Schema 信息 scala> df.printSchema root |-- age: long (nullable = true) |-- username: string (nullable = true) # 只查看"username" 列数据 scala> df.select("username" ).show +--------+ |username| +--------+ |zhangsan| | lisi| | wangwu| +--------+ # 查看"username" 列数据以及"age+1" 数据 # 涉及到运算的时候, 每列都必须使用$, 或者采用引号表达式:单引号+字段名 scala> df.select($"username" , $"age" +1).show +--------+---------+ |username|(age + 1)| +--------+---------+ |zhangsan| 31| | lisi| 21| | wangwu| 41| +--------+---------+ scala> df.select('username, ' age+1).show +--------+---------+ |username|(age + 1)| +--------+---------+ |zhangsan| 31| | lisi| 21| | wangwu| 41| +--------+---------+ scala> df.select('username, ' age+1 as "newage" ).show +--------+------+ |username|newage| +--------+------+ |zhangsan| 31| | lisi| 21| | wangwu| 41| +--------+------+ # 查看"age" 大于"30" 的数据 scala> df.filter('age > 30).show +---+--------+ |age|username| +---+--------+ | 40| wangwu| +---+--------+ # 按照"age"分组,查看数据条数 scala> df.groupBy("age").count.show +---+-----+ |age|count| +---+-----+ | 30| 1| | 20| 1| | 40| 1| +---+-----+
RDD 转换为 DataFrame 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 实际开发中,一般通过样例类将 RDD 转换为 DataFrame scala> case class User(name:String, age:Int) defined class User # RDD 转换为 DataFrame scala> val df = sc.makeRDD(List(("zhangsan" ,30), ("lisi" ,40))).map(t => User(t._1, t._2)).toDF df: org.apache.spark.sql.DataFrame = [name: string, age: int] # 展示数据 scala> df.select("name" , "age" ).show +--------+---+ | name|age| +--------+---+ |zhangsan| 30| | lisi| 40| +--------+---+
DataFrame 转换为 RDD 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # DataFrame 转换为 RDD # 此时得到的 RDD 存储类型为 Row scala> val rdd = df.rdd rdd: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[60] at rdd at <console>:24 scala> val array = rdd.collect array: Array[org.apache.spark.sql.Row] = Array([zhangsan,30], [lisi,40]) scala> array(0) res24: org.apache.spark.sql.Row = [zhangsan,30] scala> array(0)(0) res25: Any = zhangsan scala> array(0).getAs[String]("name" ) res27: String = zhangsan
DataSet 创建 DataSet 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 # 使用样例类序列创建 DataSet scala> case class Person(name: String, age: Long) defined class Person scala> val caseClassDS = Seq(Person("zhangsan" ,2)).toDS() caseClassDS: org.apache.spark.sql.Dataset[Person] = [name: string, age: bigint] scala> caseClassDS.show +--------+---+ | name|age| +--------+---+ |zhangsan| 2| +--------+---+ # 使用基本类型的序列创建 DataSet scala> val ds = Seq(1,2,3,4,5).toDS ds: org.apache.spark.sql.Dataset[Int] = [value: int] scala> ds.show +-----+ |value| +-----+ | 1| | 2| | 3| | 4| | 5| +-----+
RDD 转换为 DataSet 1 2 3 4 5 6 7 8 9 10 11 12 13 scala> case class User(name:String, age:Int) defined class User scala> val ds = sc.makeRDD(List(("zhangsan" ,30), ("lisi" ,49))).map(t=>User(t._1, t._2)).toDS ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int] scala> ds.show +--------+---+ | name|age| +--------+---+ |zhangsan| 30| | lisi| 49| +--------+---+
DataSet 转换为 RDD 1 2 3 4 5 6 7 8 9 10 11 scala> case class User(name:String, age:Int) defined class User scala> val ds = sc.makeRDD(List(("zhangsan" ,30), ("lisi" ,49))).map(t=>User(t._1, t._2)).toDS ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int] scala> val rdd = ds.rdd rdd: org.apache.spark.rdd.RDD[User] = MapPartitionsRDD[70] at rdd at <console>:23 scala> rdd.collect res32: Array[User] = Array(User(zhangsan,30), User(lisi,49))
DataFrame 和 和 DataSet 转换 DataFrame 转换为 DataSet 1 2 3 4 5 6 7 8 scala> case class User(name:String, age:Int) defined class User scala> val df = sc.makeRDD(List(("zhangsan" ,30), ("lisi" ,49))).toDF("name" ,"age" ) df: org.apache.spark.sql.DataFrame = [name: string, age: int] scala> val ds = df.as[User] ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int]
DataSet 转换为 DataFrame 1 2 3 4 5 scala> val ds = df.as[User] ds: org.apache.spark.sql.Dataset[User] = [name: string, age: int] scala> val df = ds.toDF df: org.apache.spark.sql.DataFrame = [name: string, age: int]
IDEA 开发 SparkSQL 添加依赖 1 2 3 4 5 <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-sql_2.12</artifactId > <version > 3.2.1</version > </dependency >
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 object Spark01_SparkSQL_Basic def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkSQL" ) val spark: SparkSession = SparkSession .builder().config(sparkConf).getOrCreate() import spark.implicits._ val df: DataFrame = spark.read.json("data/user.json" ) df.createOrReplaceTempView("user" ) spark.sql("SELECT * FROM user" ).show() spark.sql("SELECT username, age FROM user" ).show() spark.sql("SELECT avg(age) FROM user" ).show() df.select("username" , "age" ).show() df.select($"age" + 1 ).show df.select('age + 1 ).show val seq = Seq (1 , 2 , 3 , 4 ) val ds: Dataset [Int ] = seq.toDS() ds.show() val rdd: RDD [(Int , String , Int )] = spark.sparkContext.makeRDD(List ((1 , "zhangsan" , 30 ), (2 , "lisi" , 40 ))) val dataFrame: DataFrame = rdd.toDF("id" , "name" , "age" ) val rowRdd: RDD [Row ] = dataFrame.rdd val dataSet: Dataset [User ] = dataFrame.as[User ] val frame: DataFrame = dataSet.toDF() val set: Dataset [User ] = rdd.map { case (id, name, age) => { User (id, name, age) } }.toDS() val userRdd: RDD [User ] = set.rdd spark.close() } case class User (id: Int , name: String , age: Int ) }
用户自定义函数 UDF 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 object Spark02_SparkSQL_UDF def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkSQL" ) val spark: SparkSession = SparkSession .builder().config(sparkConf).getOrCreate() import spark.implicits._ val df: DataFrame = spark.read.json("data/user.json" ) df.createOrReplaceTempView("user" ) spark.udf.register("prefixName" , (name: String ) => { "Name: " + name }) spark.sql("SELECT age, prefixName(username) FROM user" ).show spark.close() } }
UDAF 弱类型,不推荐使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 object Spark04_SparkSQL_UDAF_New def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkSQL" ) val spark: SparkSession = SparkSession .builder().config(sparkConf).getOrCreate() val df: DataFrame = spark.read.json("data/user.json" ) df.createOrReplaceTempView("user" ) spark.udf.register("ageAvg" , functions.udaf(new MyAvgUDAF )) spark.sql("SELECT ageAvg(age) FROM user" ).show spark.close() } case class Buff (var total: Long , var count: Long ) class MyAvgUDAF extends Aggregator [Long , Buff , Long ] override def zero Buff = { Buff (0 L, 0 L) } override def reduce Buff , in: Long ): Buff = { buff.total += in buff.count += 1 buff } override def merge Buff , buff2: Buff ): Buff = { buff1.total += buff2.total buff1.count += buff2.count buff1 } override def finish Buff ): Long = { buff.total / buff.count } override def bufferEncoder Encoder [Buff ] = Encoders .product override def outputEncoder Encoder [Long ] = Encoders .scalaLong } }
强类型,推荐使用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 object Spark05_SparkSQL_UDAF_Old def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkSQL" ) val spark: SparkSession = SparkSession .builder().config(sparkConf).getOrCreate() import spark.implicits._ val df: DataFrame = spark.read.json("data/user.json" ) val ds: Dataset [User ] = df.as[User ] val udafCol: TypedColumn [User , Long ] = new MyAvgUDAF ().toColumn ds.select(udafCol).show spark.close() } case class User (username: String , age: Long ) case class Buff (var total: Long , var count: Long ) class MyAvgUDAF extends Aggregator [User , Buff , Long ] override def zero Buff = { Buff (0 L, 0 L) } override def reduce Buff , in: User ): Buff = { buff.total += in.age buff.count += 1 buff } override def merge Buff , buff2: Buff ): Buff = { buff1.total += buff2.total buff1.count += buff2.count buff1 } override def finish Buff ): Long = { buff.total / buff.count } override def bufferEncoder Encoder [Buff ] = Encoders .product override def outputEncoder Encoder [Long ] = Encoders .scalaLong } }
数据的加载和保存 通用的加载和保存方式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 # spark.read.load 是加载数据的通用方法 scala> spark.read.format("…" )[.option("…" )].load("…" ) # 案例 scala> val df = spark.read.format("json" ).load("bin/input/user.json" ) df: org.apache.spark.sql.DataFrame = [age: bigint, username: string] scala> df.show +---+--------+ |age|username| +---+--------+ | 30|zhangsan| | 20| lisi| | 40| wangwu| +---+--------+ scala> spark.sql("SELECT * FROM json.`bin/input/user.json`" ).show 22/05/29 10:06:43 WARN ObjectStore: Failed to get database global_temp, returning NoSuchObjectException 22/05/29 10:06:43 WARN ObjectStore: Failed to get database json, returning NoSuchObjectException +---+--------+ |age|username| +---+--------+ | 30|zhangsan| | 20| lisi| | 40| wangwu| +---+--------+
format(“…”):指定加载的数据类型,包括”csv”、”jdbc”、”json”、”orc”、”parquet” 和 “textFile”;
load(“…”):在”csv”、”jdbc”、”json”、”orc”、”parquet”和”textFile”格式下需要传入加载数据的路径;
option(“…”):在”jdbc”格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable
1 2 3 4 5 6 # df.write.save 是保存数据的通用方法 scala> df.write.format("…" )[.option("…" )].save("…" ) # 案例 scala> df.write.format("json" ).save("bin/output" )
format(“…”):指定保存的数据类型,包括”csv”、”jdbc”、”json”、”orc”、”parquet”和 “textFile”;
save (“…”):在”csv”、”orc”、”parquet”和”textFile”格式下需要传入保存数据的路径;
option(“…”):在”jdbc”格式下需要传入 JDBC 相应参数,url、user、password 和 dbtable。保存操作可以使用 SaveMode, 用来指明如何处理数据,使用 mode()方法来设置。有一点很重要: 这些 SaveMode 都是没有加锁的, 也不是原子操作。
Scala/Java
Any Language
Meaning
SaveMode.ErrorIfExists(default)
“error”(default)
如果文件已经存在则抛出异常
SaveMode.Append
“append”
如果文件已经存在则追加
SaveMode.Overwrite
“overwrite”
如果文件已经存在则覆盖
SaveMode.Ignore
“ignore”
如果文件已经存在则忽略
Parquet Spark SQL 的默认数据源为 Parquet 格式。Parquet 是一种能够有效存储嵌套数据的列式存储格式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 # 加载数据 scala> val df = spark.read.load("examples/src/main/resources/users.parquet" ) df: org.apache.spark.sql.DataFrame = [name: string, favorite_color: string ... 1 more field] scala> df.show +------+--------------+----------------+ | name|favorite_color|favorite_numbers| +------+--------------+----------------+ |Alyssa| null| [3, 9, 15, 20]| | Ben| red| []| +------+--------------+----------------+ # 保存数据 scala> df.write.mode("append" ).save("bin/output" )
JSON Spark SQL 能够自动推测 JSON 数据集的结构,并将它加载为一个 Dataset[Row]. 可以通过 SparkSession.read.json()去加载 JSON 文件。注意:Spark 读取的 JSON 文件不是传统的 JSON 文件,每一行都应该是一个 JSON 串。格式如下:
1 2 3 {"name" :"Michael" } {"name" :"Andy" , "age" :30 } [{"name" :"Justin" , "age" :19 },{"name" :"Justin" , "age" :19 }]
CSV Spark SQL 可以配置 CSV 文件的列表信息,读取 CSV 文件,CSV 文件的第一行设置为数据列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 # 数据源 name;age;job Jorge;30;Developer Bob;32;Developer # 读取 CSV 文件 scala> val df = spark.read.format("csv" ).option("sep" , ";" ).option("inferSchema" ,"true" ).option("header" , "true" ).load("examples/src/main/resources/people.csv" ) df: org.apache.spark.sql.DataFrame = [name: string, age: int ... 1 more field] scala> df.show +-----+---+---------+ | name|age| job| +-----+---+---------+ |Jorge| 30|Developer| | Bob| 32|Developer| +-----+---+---------+
MySQL Spark SQL 可以通过 JDBC 从关系型数据库中读取数据的方式创建 DataFrame,通过对 DataFrame 一系列的计算后,还可以将数据再写回关系型数据库中。如果使用 spark-shell 操作,可在启动 shell 时指定相关的数据库驱动路径或者将相关的数据库驱动放到 spark 的类路径下。
1 bin/spark-shell --jars mysql-connector-java-5.1.27-bin.jar
我们这里只演示在 Idea 中通过 JDBC 对 Mysql 进行操作:
导入依赖 1 2 3 4 5 <dependency > <groupId > mysql</groupId > <artifactId > mysql-connector-java</artifactId > <version > 5.1.47</version > </dependency >
读写数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 object Spark06_SparkSQL_JDBC def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkSQL" ) val spark: SparkSession = SparkSession .builder().config(sparkConf).getOrCreate() val df: DataFrame = spark.read.format("jdbc" ) .option("url" , "jdbc:mysql://localhost:3306/spark-sql" ) .option("driver" , "com.mysql.jdbc.Driver" ) .option("user" , "root" ) .option("password" , "root" ) .option("dbtable" , "user" ) .load() df.show() df.write.format("jdbc" ) .option("url" , "jdbc:mysql://localhost:3306/spark-sql" ) .option("driver" , "com.mysql.jdbc.Driver" ) .option("user" , "root" ) .option("password" , "root" ) .option("dbtable" , "user_new" ) .mode(SaveMode .Append ) .save spark.close() } }
Hive Apache Hive 是 Hadoop 上的 SQL 引擎,Spark SQL 编译时可以包含 Hive 支持,也可以不包含。包含 Hive 支持的 Spark SQL 可以支持 Hive 表访问、UDF (用户自定义函数)以及 Hive 查询语言(HiveQL/HQL)等。
内嵌 Hive 如果使用 Spark 内嵌的 Hive,则什么都不用做,直接使用即可。
Hive 的元数据存储在 derby 中, 默认仓库地址:$SPARK_HOME/spark-warehouse
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 # 创建表 scala> spark.sql("show tables" ).show +---------+---------+-----------+ |namespace|tableName|isTemporary| +---------+---------+-----------+ +---------+---------+-----------+ scala> spark.sql("CREATE TABLE user(id int, name String, age int) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' '" ) scala> spark.sql("show tables" ).show +---------+---------+-----------+ |namespace|tableName|isTemporary| +---------+---------+-----------+ | default| user| false| +---------+---------+-----------+ # 添加数据 [eitan@SparkOrigin ~]$ vim /opt/module/spark-local-3.2.1/data/user.txt 1 zhangsan 20 2 lisi 30 3 wangwu 40 scala> spark.sql("LOAD DATA LOCAL INPATH '/opt/module/spark-local-3.2.1/data/user.txt/' INTO TABLE user" ) res13: org.apache.spark.sql.DataFrame = [] scala> spark.sql("SELECT * FROM user" ).show +---+--------+---+ | id| name|age| +---+--------+---+ | 1|zhangsan| 20| | 2| lisi| 30| | 3| wangwu| 40| +---+--------+---+
外部的 HIVE 这里选用的 Hive 部署方式可用查看 Hadoop(一):集群搭建 和 Hadoop(三):Hive
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 # 1.启动 Hive 环境 # 启动 msql [eitan@hadoop102 ~]$ systemctl start mysqld # 启动 hdfs 集群 [eitan@hadoop102 ~]$ /opt/module/hadoop-3.3.2/sbin/start-dfs.sh # 启动 metastore 服务 [eitan@hadoop102 ~]$ nohup /opt/module/apache-hive-3.1.3/bin/hive --service metastore > /home/eitan/log/metastore.out 2>&1 & # 启动 hiveserver2 服务 [eitan@hadoop103 ~]$ nohup /opt/module/apache-hive-3.1.3/bin/hiveserver2 > /home/eitan/log/hiveserver2.out 2>&1 & # 2.Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 $SPARK_HOME /conf 目录下 [eitan@hadoop103 ~]$ scp /opt/module/apache-hive-3.1.3/conf/hive-site.xml eitan@192.168.203.150:/opt/module/spark-local-3.2.1/conf、 # 3.把 Mysql 的驱动 copy 到 jars/ 目录下 [eitan@hadoop103 ~]$ scp /opt/module/apache-hive-3.1.3/lib/mysql-connector-java-8.0.29.jar eitan@192.168.203.150:/opt/module/spark-local-3.2.1/jars # 4.如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下,我访问的到 # 5.重启 spark-shell scala> spark.sql("show databases" ).show +---------+ |namespace| +---------+ | default| | itcast| +---------+
运行 Spark SQL CLI 1 2 3 4 5 6 [eitan@SparkOrigin ~]$ /opt/module/spark-local-3.2.1/bin/spark-sql spark-sql> show databases; default itcast Time taken: 0.046 seconds, Fetched 2 row(s)
运行 Spark beeline Spark Thrift Server 是 Spark 社区基于 HiveServer2 实现的一个 Thrift 服务。旨在无缝兼容 HiveServer2。因为 Spark Thrift Server 的接口和协议都和 HiveServer2 完全一致,因此我们部署好 Spark Thrift Server 后,可以直接使用 hive 的 beeline 访问 Spark Thrift Server 执行相关语句。Spark Thrift Server 的目的也只是取代 HiveServer2,因此它依旧可以和 Hive Metastore 进行交互,获取到 hive 的元数据。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 # 1.Spark 要接管 Hive 需要把 hive-site.xml 拷贝到 $SPARK_HOME /conf 目录下 [eitan@hadoop103 ~]$ scp /opt/module/apache-hive-3.1.3/conf/hive-site.xml eitan@192.168.203.150:/opt/module/spark-local-3.2.1/conf、 # 2.把 Mysql 的驱动 copy 到 jars/ 目录下 [eitan@hadoop103 ~]$ scp /opt/module/apache-hive-3.1.3/lib/mysql-connector-java-8.0.29.jar eitan@192.168.203.150:/opt/module/spark-local-3.2.1/jars # 3.如果访问不到 hdfs,则需要把 core-site.xml 和 hdfs-site.xml 拷贝到 conf/目录下,我访问的到 # 4.启动 Thrift Server [eitan@SparkOrigin ~]$ /opt/module/spark-local-3.2.1/sbin/start-thriftserver.sh # 5.使用 beeline 连接 Thrift Server [eitan@SparkOrigin ~]$ /opt/module/spark-local-3.2.1/bin/beeline -u jdbc:hive2://192.168.203.103:10000 -n eitan log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell). log4j:WARN Please initialize the log4j system properly. log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Connecting to jdbc:hive2://192.168.203.103:10000 Connected to: Apache Hive (version 3.1.3) Driver: Hive JDBC (version 2.3.9) Transaction isolation: TRANSACTION_REPEATABLE_READ Beeline version 2.3.9 by Apache Hive 0: jdbc:hive2://192.168.203.103:10000> show databases; +----------------+ | database_name | +----------------+ | default | | itcast | +----------------+
代码操作 Hive 1 2 3 4 5 6 <dependency > <groupId > org.apache.spark</groupId > <artifactId > spark-hive_2.12</artifactId > <version > 3.2.1</version > </dependency >
1 2 3 4 5 6 7 8 9 10 11 12 13 object Spark07_SparkSQL_Hive def main Array [String ]): Unit = { val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkSQL" ) val spark: SparkSession = SparkSession .builder().enableHiveSupport().config(sparkConf).getOrCreate() spark.sql("show databases" ).show() spark.close() } }
SparkSQL 项目实战 数据准备 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 object Spark08_SparkSQL_PrepareData def main Array [String ]): Unit = { System .setProperty("HADOOP_USER_NAME" , "eitan" ) val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkSQL" ) val spark: SparkSession = SparkSession .builder().enableHiveSupport().config(sparkConf).getOrCreate() spark.sql("USE atguigu" ) spark.sql( """ |CREATE TABLE `user_visit_action` |( | `date` string, | `user_id` bigint, | `session_id` string, | `page_id` bigint, | `action_time` string, | `search_keyword` string, | `click_category_id` bigint, | `click_product_id` bigint, | `order_category_ids` string, | `order_product_ids` string, | `pay_category_ids` string, | `pay_product_ids` string, | ` city_id ` bigint |) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' |""" .stripMargin) spark.sql("LOAD DATA LOCAL INPATH 'data/user_visit_action.txt' INTO TABLE user_visit_action" ) spark.sql( """ |CREATE TABLE `product_info` |( | `product_id` bigint, | `product_name` string, | `extend_info` string |) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' |""" .stripMargin) spark.sql("LOAD DATA LOCAL INPATH 'data/product_info.txt' INTO TABLE product_info" ) spark.sql( """ |CREATE TABLE `city_info` |( | `city_id` bigint, | `city_name` string, | `area` string |) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' |""" .stripMargin) spark.sql("LOAD DATA LOCAL INPATH 'data/city_info.txt' INTO TABLE city_info" ) spark.sql("SELECT * FROM city_info" ).show spark.close() } }
需求说明 这里的热门商品是从点击量的维度来看的,计算各个区域前三大热门商品,并备注上每个商品在主要城市中的分布比例,超过两个城市用其他显示。
例如:
地区
商品名称
点击次数
城市备注
华北
商品 A
100000
北京 21.2%,天津 13.2%,其他 65.6%
华北
商品 P
80200
北京 63.0%,太原 10%,其他 27.0%
华北
商品 M
40000
北京 63.0%,太原 10%,其他 27.0%
东北
商品 J
92000
大连 28%,辽宁 17.0%,其他 55.0%
代码实现 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 object Spark09_SparkSQL_Search def main Array [String ]): Unit = { System .setProperty("HADOOP_USER_NAME" , "eitan" ) val sparkConf: SparkConf = new SparkConf ().setMaster("local[*]" ).setAppName("sparkSQL" ) val spark: SparkSession = SparkSession .builder().enableHiveSupport().config(sparkConf).getOrCreate() spark.sql("USE atguigu" ) spark.sql( """ |SELECT b.product_name, | c.city_name, | c.area |FROM user_visit_action a | JOIN product_info b ON a.click_product_id = b.product_id | JOIN city_info c ON a.city_id = c.city_id |""" .stripMargin).createOrReplaceTempView("t1" ) spark.udf.register("cityRemark" , functions.udaf(new CityRemarkUDAF )) spark.sql( """ |SELECT area, | product_name, | count(*) AS clickCnt, | cityRemark(city_name) AS cityRemark |FROM t1 |GROUP BY area, product_name |""" .stripMargin).createOrReplaceTempView("t2" ) spark.sql( """ |SELECT *, | rank() OVER (PARTITION BY area ORDER BY clickCnt DESC) AS rank |FROM t2 |""" .stripMargin).createOrReplaceTempView("t3" ) spark.sql("SELECT * FROM t3 WHERE rank <= 3" ).show(false ) spark.close() } case class Buff (var count: Long , map: mutable.Map [String , Long ] ) class CityRemarkUDAF extends Aggregator [String , Buff , String ] override def zero Buff = { Buff (0 L, mutable.Map ()) } override def reduce Buff , in: String ): Buff = { buff.count += 1 val newCnt: Long = buff.map.getOrElse(in, 0 L) + 1 buff.map.update(in, newCnt) buff } override def merge Buff , buff2: Buff ): Buff = { buff2.map.foreach { case (cityName, cnt) => { val newCnt: Long = buff1.map.getOrElse(cityName, 0 L) + cnt buff1.map.update(cityName, newCnt) } } buff1.count += buff2.count buff1 } override def finish Buff ): String = { val remarkList = ListBuffer [String ]() val cityCntList: List [(String , Long )] = buff.map.toList.sortBy(_._2)(Ordering .Long .reverse) val total: Long = buff.count val list: List [(String , Long )] = cityCntList.take(2 ) var rsum = 0 L; list.foreach { case (city, cnt) => { val ratio: Long = cnt * 100 / total remarkList.append(s"${city} ${ratio} %" ) rsum += ratio } } if (cityCntList.size > 2 ) { remarkList.append(s"其他 ${100 - rsum} %" ) } remarkList.mkString("," ) } override def bufferEncoder Encoder [Buff ] = Encoders .product override def outputEncoder Encoder [String ] = Encoders .STRING } }