本文为学习笔记,对应视频教程来自【尚硅谷】电商数仓V5.0
项目需求及架构设计 项目需求分析
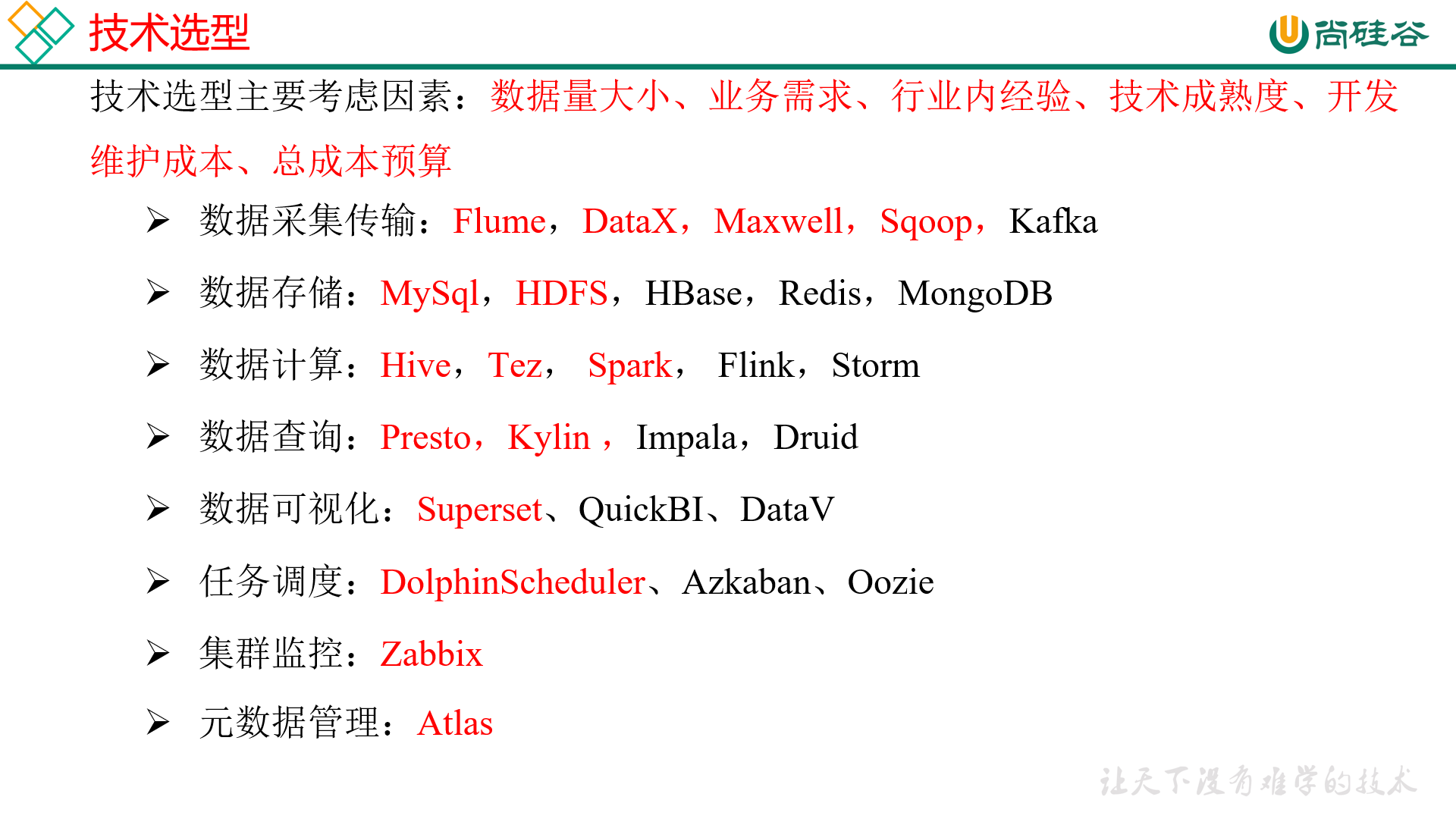
项目框架 技术选型
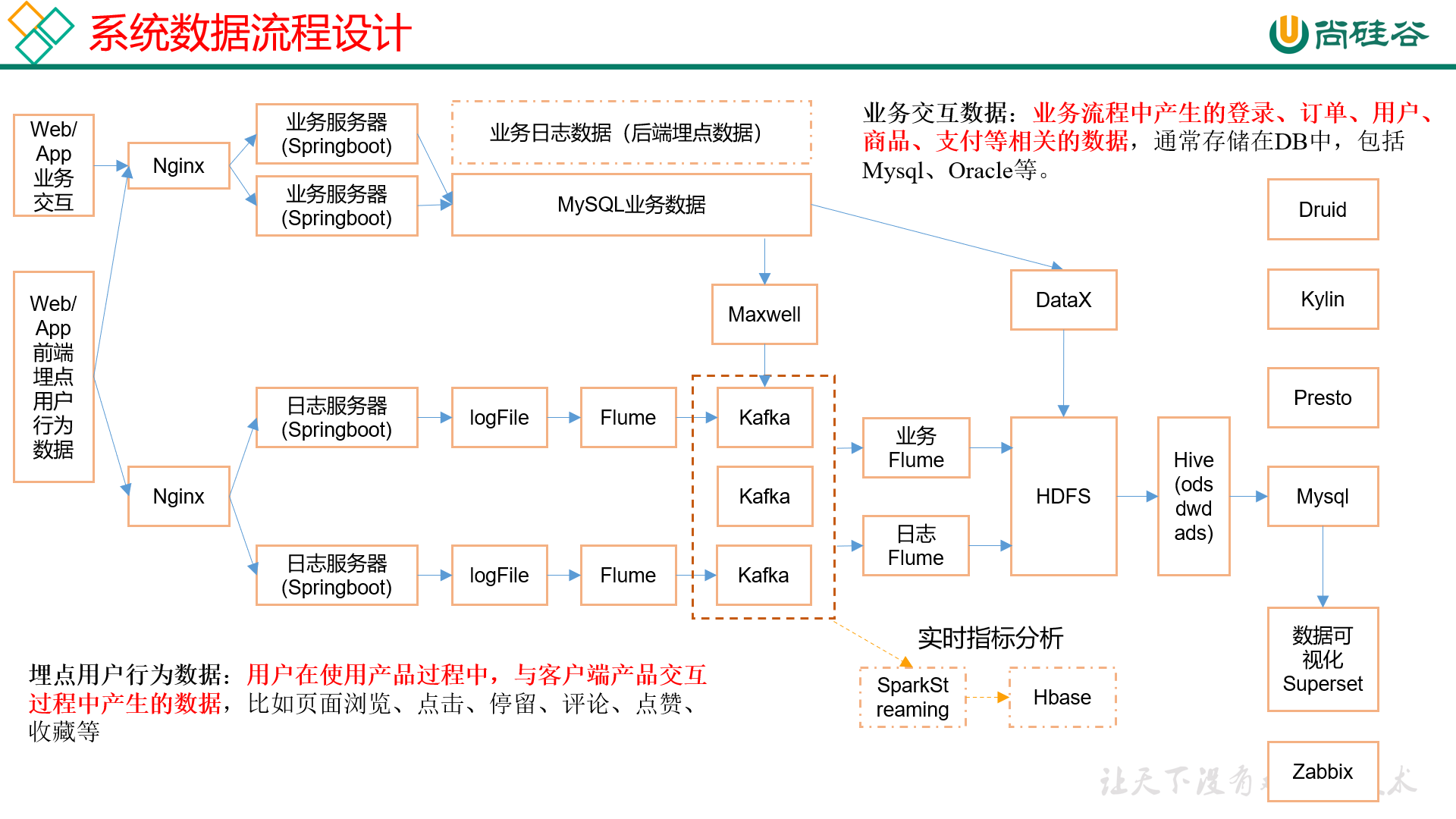
系统数据流程设计
框架版本选型
产品
版本
Java
1.8
Hadoop
3.1.3
Hive
3.1.2
Flume
1.9.0
Zookeeper
3.5.7
Kafka
2.4.1
DataX
3.0
Maxwell
1.29.2
服务器选型
集群资源规划设计
测试集群服务器规划
服务名称
子服务
服务器hadoop102/6G
服务器hadoop103/4G
服务器hadoop104/2G
HDFS
NameNode
✓
DataNode
✓
✓
✓
SecondaryNameNode
✓
Yarn
NodeManager
✓
✓
✓
ResourceManager
✓
Zookeeper
Zookeeper Server
✓
✓
✓
Flume(采集日志)
Flume
✓
✓
Kafka
Kafka
✓
✓
✓
Flume(消费Kafka)
Flume
✓
Hive
Hive
✓
MySQL
MySQL
✓
DataX
DataX
✓
Maxwell
Maxwell
✓
Presto
Coordinator
✓
Worker
✓
✓
✓
DolphinScheduler
MasterServer
✓
WorkerServer
✓
✓
✓
Druid
Druid
✓
✓
✓
Kylin
✓
Hbase
HMaster
✓
HRegionServer
✓
✓
✓
Superset
✓
Atlas
✓
Solr
Jar
✓
✓
✓
用户行为日志 用户行为日志概述 用户行为日志的内容,主要包括用户的各项行为信息 以及行为所处的环境信息 。收集这些信息的主要目的是优化产品和为各项分析统计指标提供数据支撑。收集这些信息的手段通常为埋点 。
目前主流的埋点方式,有代码埋点(前端/后端)、可视化埋点、全埋点等。
代码埋点 是通过调用埋点SDK函数,在需要埋点的业务逻辑功能位置调用接口,上报埋点数据。例如,我们对页面中的某个按钮埋点后,当这个按钮被点击时,可以在这个按钮对应的 OnClick 函数里面调用SDK提供的数据发送接口,来发送数据。
可视化埋点 只需要研发人员集成采集 SDK,不需要写埋点代码,业务人员就可以通过访问分析平台的“圈选”功能,来“圈”出需要对用户行为进行捕捉的控件,并对该事件进行命名。圈选完毕后,这些配置会同步到各个用户的终端上,由采集 SDK 按照圈选的配置自动进行用户行为数据的采集和发送。
全埋点 是通过在产品中嵌入SDK,前端自动采集页面上的全部用户行为事件,上报埋点数据,相当于做了一个统一的埋点。然后再通过界面配置哪些数据需要在系统里面进行分析。
用户行为日志内容 本项目收集和分析的用户行为信息主要有页面浏览记录、动作记录、曝光记录、启动记录和错误记录。
页面浏览记录 ,记录的是访客对页面的浏览行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息及页面信息等。动作记录 ,记录的是用户的业务操作行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息及动作目标对象信息等。曝光记录 ,记录的是曝光行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息及曝光对象信息等。启动记录 ,记录的是用户启动应用的行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息、启动类型及开屏广告信息等。错误记录 ,记录的是用户在使用应用过程中的报错行为,该行为的环境信息主要有用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息、以及可能与报错相关的页面信息、动作信息、曝光信息和动作信息。
用户行为日志格式 页面日志 页面日志,以页面浏览为单位,即一个页面浏览记录,生成一条页面埋点日志。一条完整的页面日志包含:一个页面浏览记录,若干个用户在该页面所做的动作记录,若干个该页面的曝光记录,以及一个在该页面发生的报错记录。除上述行为信息,页面日志还包含了这些行为所处的各种环境信息,包括用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 { "common" : { -- 环境信息 "ar" : "230000" , -- 地区编码 "ba" : "iPhone" , -- 手机品牌 "ch" : "Appstore" , -- 渠道 "is_new" : "1" ,--是否首日使用,首次使用的当日,该字段值为1,过了24:00 ,该字段置为0 。 "md" : "iPhone 8" , -- 手机型号 "mid" : "YXfhjAYH6As2z9Iq" , -- 设备id "os" : "iOS 13.2.9" , -- 操作系统 "uid" : "485" , -- 会员id "vc" : "v2.1.134" -- app版本号 }, "actions" : [ --动作(事件) { "action_id" : "favor_add" , --动作id "item" : "3" , --目标id "item_type" : "sku_id" , --目标类型 "ts" : 1585744376605 --动作时间戳 } ], "displays" : [ { "displayType" : "query" , -- 曝光类型 "item" : "3" , -- 曝光对象id "item_type" : "sku_id" , -- 曝光对象类型 "order" : 1 , --出现顺序 "pos_id" : 2 --曝光位置 }, { "displayType" : "promotion" , "item" : "6" , "item_type" : "sku_id" , "order" : 2 , "pos_id" : 1 }, { "displayType" : "promotion" , "item" : "9" , "item_type" : "sku_id" , "order" : 3 , "pos_id" : 3 }, { "displayType" : "recommend" , "item" : "6" , "item_type" : "sku_id" , "order" : 4 , "pos_id" : 2 }, { "displayType" : "query " , "item" : "6" , "item_type" : "sku_id" , "order" : 5 , "pos_id" : 1 } ], "page" : { --页面信息 "during_time" : 7648 , -- 持续时间毫秒 "item" : "3" , -- 目标id "item_type" : "sku_id" , -- 目标类型 "last_page_id" : "login" , -- 上页类型 "page_id" : "good_detail" , -- 页面ID "sourceType" : "promotion" -- 来源类型 }, "err" :{ --错误 "error_code" : "1234" , --错误码 "msg" : "***********" --错误信息 }, "ts" : 1585744374423 --跳入时间戳 }
启动日志 启动日志以启动为单位,及一次启动行为,生成一条启动日志。一条完整的启动日志包括一个启动记录,一个本次启动时的报错记录,以及启动时所处的环境信息,包括用户信息、时间信息、地理位置信息、设备信息、应用信息、渠道信息等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 { "common" : { "ar" : "370000" , "ba" : "Honor" , "ch" : "wandoujia" , "is_new" : "1" , "md" : "Honor 20s" , "mid" : "eQF5boERMJFOujcp" , "os" : "Android 11.0" , "uid" : "76" , "vc" : "v2.1.134" }, "start" : { "entry" : "icon" , --icon手机图标 notice 通知 install 安装后启动 "loading_time" : 18803 , --启动加载时间 "open_ad_id" : 7 , --广告页ID "open_ad_ms" : 3449 , -- 广告总共播放时间 "open_ad_skip_ms" : 1989 -- 用户跳过广告时点 }, "err" :{ --错误 "error_code" : "1234" , --错误码 "msg" : "***********" --错误信息 }, "ts" : 1585744304000 }
模拟生成用户行为日志 环境准备 服务器准备 准备hadoop102、hadoop103、hadoop104三台虚拟机。参考Hadoop(一):集群搭建
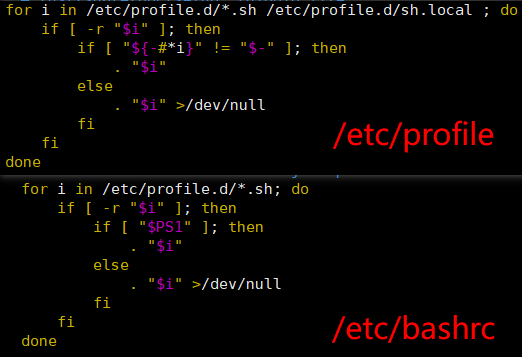
环境变量配置说明 Linux的环境变量可在多个文件中配置,如/etc/profile,/etc/profile.d/*.sh,/.bashrc,/.bash_profile等,下面说明上述几个文件之间的关系和区别。
bash的运行模式可分为login shell和non-login shell。
我们通过终端,输入用户名、密码,登录系统之后,得到就是一个login shell
执行以下命令ssh hadoop103 command,在hadoop103执行command的就是一个non-login shell。
这两种shell的主要区别在于,它们启动时会加载不同的配置文件,login shell启动时会加载/etc/profile,/.bash_profile,/.bashrc,non-login shell启动时会加载~/.bashrc。即login shell会多加载/etc/profile文件。
而在加载/.bashrc(实际是/.bashrc中加载的/etc/bashrc)或/etc/profile时,都会执行如下代码片段
因此不管是login shell还是non-login shell,启动时都会加载/etc/profile.d/*.sh中的环境变量。而login shell会多加载/etc/profile.d/sh.local 和 /etc/profile 文件。
模拟数据 上传模拟器 1 2 # 将application.yml、gmall2020-mock-log-2021-10-10.jar、path.json、logback.xml上传到hadoop102的/opt/module/applog目录下 [eitan@hadoop102 ~]$ mkdir /opt/module/applog
配置文件说明 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 logging.config: "./logback.xml" mock.date: "2020-06-14" logging.config: "./logback.xml" mock.date: "2020-06-14" logging.config: "./logback.xml" mock.date: "2020-06-14" mock.type: "log" mock.url: "http://localhost:8090/applog" mock: kafka-server: "hdp1:9092,hdp2:9092,hdp3:9092" kafka-topic: "ODS_BASE_LOG" mock.startup.count: 200 mock.max.mid: 1000000 mock.max.uid: 1000 mock.max.sku-id: 35 mock.page.during-time-ms: 20000 mock.error.rate: 3 mock.log.sleep: 20 mock.detail.source-type-rate: "40:25:15:20" mock.if_get_coupon_rate: 75 mock.max.coupon-id: 3 mock.search.keyword: "图书,小米,iphone11,电视,口红,ps5,苹果手机,小米盒子" mock.sku-weight.male: "10:10:10:10:10:10:10:5:5:5:5:5:10:10:10:10:12:12:12:12:12:5:5:5:5:3:3:3:3:3:3:3:3:10:10" mock.sku-weight.female: "1:1:1:1:1:1:1:5:5:5:5:5:1:1:1:1:2:2:2:2:2:8:8:8:8:15:15:15:15:15:15:15:15:1:1"
application.yml文件,可以根据需求生成对应日期的用户行为日志。
1 2 3 4 5 6 7 8 9 10 [ {"path" :["home" ,"good_list" ,"good_detail" ,"cart" ,"trade" ,"payment" ],"rate" :20 }, {"path" :["home" ,"search" ,"good_list" ,"good_detail" ,"login" ,"good_detail" ,"cart" ,"trade" ,"payment" ],"rate" :30 }, {"path" :["home" ,"search" ,"good_list" ,"good_detail" ,"login" ,"register" ,"good_detail" ,"cart" ,"trade" ,"payment" ],"rate" :20 }, {"path" :["home" ,"mine" ,"orders_unpaid" ,"trade" ,"payment" ],"rate" :10 }, {"path" :["home" ,"mine" ,"orders_unpaid" ,"good_detail" ,"good_spec" ,"comment" ,"trade" ,"payment" ],"rate" :5 }, {"path" :["home" ,"mine" ,"orders_unpaid" ,"good_detail" ,"good_spec" ,"comment" ,"home" ],"rate" :5 }, {"path" :["home" ,"good_detail" ],"rate" :20 }, {"path" :["home" ],"rate" :10 } ]
path.json文件,用来配置访问路径,可以根据需求,灵活配置用户访问路径。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 <?xml version="1.0" encoding="UTF-8"?> <configuration > <property name ="LOG_HOME" value ="/opt/module/applog/log" /> <appender name ="console" class ="ch.qos.logback.core.ConsoleAppender" > <encoder > <pattern > %msg%n</pattern > </encoder > </appender > <appender name ="rollingFile" class ="ch.qos.logback.core.rolling.RollingFileAppender" > <rollingPolicy class ="ch.qos.logback.core.rolling.TimeBasedRollingPolicy" > <fileNamePattern > ${LOG_HOME}/app.%d{yyyy-MM-dd}.log</fileNamePattern > </rollingPolicy > <encoder > <pattern > %msg%n</pattern > </encoder > </appender > <logger name ="com.atguigu.gmall2020.mock.log.util.LogUtil" level ="INFO" additivity ="false" > <appender-ref ref ="rollingFile" /> <appender-ref ref ="console" /> </logger > <root level ="error" > <appender-ref ref ="console" /> </root > </configuration >
logback配置文件,可配置日志生成路径
集群日志生成脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 1.编写脚本 [eitan@hadoop102 ~]$ vim ./bin/lg.sh # !/bin/bash for i in hadoop102 hadoop103 do echo "========== $i ==========" ssh $i "cd /opt/module/applog/; java -jar gmall2020-mock-log-2021-10-10.jar >/dev/null 2>&1 &" done # 2.赋予权限 [eitan@hadoop102 ~]$ chmod u+x ./bin/lg.sh # 3.启动脚本 [eitan@hadoop102 ~]$ lg.sh ========== hadoop102 ========== ========== hadoop103 ==========
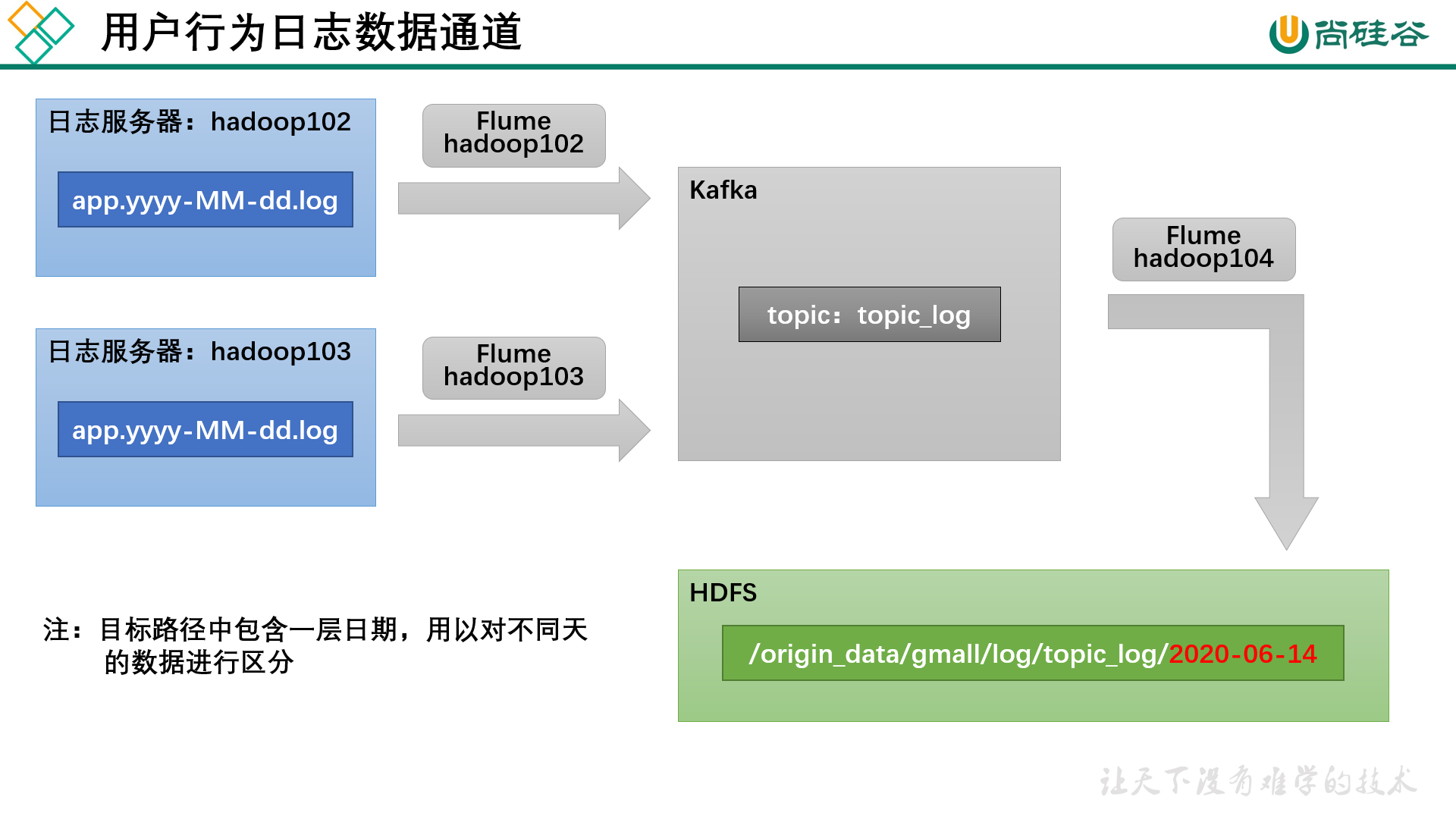
数据采集模块 数据通道
环境准备 集群所有进程查看脚本 1 2 3 4 5 6 7 8 9 [eitan@hadoop102 ~]$ vim ./bin/jpsall # !/bin/bash for i in hadoop102 hadoop103 hadoop104 do echo --------- $i ---------- ssh $i "jps $@ | grep -v Jps" done [eitan@hadoop102 ~]$ xsync ./bin/jpsall
Hadoop 集群安装 上传并解压文件 1 [eitan@hadoop102 software]$ tar -zxf hadoop-3.1.3.tar.gz -C /opt/module/
配置集群环境 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 # 1.添加环境变量 [eitan@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh # HADOOP_HOME export HADOOP_HOME=/opt/module/hadoop-3.1.3 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin # 2.修改 core-site.xml [eitan@hadoop102 ~]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml <!-- 指定NameNode的地址 --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop102:8020</value> </property> <!-- 指定hadoop数据的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/module/hadoop-3.1.3/data</value> </property> <!-- 配置HDFS网页登录使用的静态用户为eitan --> <property> <name>hadoop.http.staticuser.user</name> <value>eitan</value> </property> <!-- 配置该eitan(superUser)允许通过代理访问的主机节点 --> <property> <name>hadoop.proxyuser.eitan.hosts</name> <value>*</value> </property> <!-- 配置该eitan(superUser)允许通过代理用户所属组 --> <property> <name>hadoop.proxyuser.eitan.groups</name> <value>*</value> </property> <!-- 配置该eitan(superUser)允许通过代理的用户--> <property> <name>hadoop.proxyuser.eitan.users</name> <value>*</value> </property> # 3.修改 hdfs-site.xml [eitan@hadoop102 ~]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml <!-- nn web端访问地址--> <property> <name>dfs.namenode.http-address</name> <value>hadoop102:9870</value> </property> <!-- 2nn web端访问地址--> <property> <name>dfs.namenode.secondary.http-address</name> <value>hadoop104:9868</value> </property> <!-- 测试环境指定HDFS副本的数量1 --> <property> <name>dfs.replication</name> <value>3</value> </property> # 4.修改 yarn-site.xml [eitan@hadoop102 ~]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml <!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>hadoop103</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!-- yarn容器允许分配的最大最小内存 --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>4096</value> </property> <!-- yarn容器允许管理的物理内存大小 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <!-- 关闭yarn对物理内存和虚拟内存的限制检查 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> # 5.修改 mapred-site.xml [eitan@hadoop102 ~]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml <!-- 指定MapReduce程序运行在Yarn上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> # 6.修改 workers [eitan@hadoop102 ~]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/workers hadoop102 hadoop103 hadoop104
配置历史服务器 1 2 3 4 5 6 7 8 9 10 11 12 # 对 mapred-site.xml 添加配置 [eitan@hadoop102 ~]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/mapred-site.xml <!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>hadoop102:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>hadoop102:19888</value> </property>
配置日志的聚集 日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 # 对 yarn-site.xml 添加配置 [eitan@hadoop102 ~]$ vim /opt/module/hadoop-3.1.3/etc/hadoop/yarn-site.xml <!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://hadoop102:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
群起集群脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 # !/bin/bash if [ $# -lt 1 ] then echo "No Args Input..." exit ; fi case $1 in "start") echo " =================== 启动 hadoop集群 ===================" echo " --------------- 启动 hdfs ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh" echo " --------------- 启动 yarn ---------------" ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh" echo " --------------- 启动 historyserver ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver" ;; "stop") echo " =================== 关闭 hadoop集群 ===================" echo " --------------- 关闭 historyserver ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver" echo " --------------- 关闭 yarn ---------------" ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh" echo " --------------- 关闭 hdfs ---------------" ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh" ;; *) echo "Input Args Error..." ;; esac
Zookeeper 集群安装 上传并解压文件 1 2 3 [eitan@hadoop102 ~]$ tar -zxf /opt/software/apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/ [eitan@hadoop102 ~]$ mv /opt/module/apache-zookeeper-3.5.7-bin/ /opt/module/zookeeper-3.5.7
更改配置文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # 1.配置服务器编号,依次为2,3,4 [eitan@hadoop102 ~]$ mkdir /opt/module/zookeeper-3.5.7/zkData [eitan@hadoop102 ~]$ vim /opt/module/zookeeper-3.5.7/zkData/myid 2 # 2.配置zoo.cfg文件 [eitan@hadoop102 ~]$ vim /opt/module/zookeeper-3.5.7/conf/zoo.cfg # 修改 dataDir=/opt/module/zookeeper-3.5.7/zkData # 添加 # cluster server.2=hadoop102:2888:3888 server.3=hadoop103:2888:3888 server.4=hadoop104:2888:3888 # 3.分发并修改myid [eitan@hadoop102 ~]$ xsync /opt/module/zookeeper-3.5.7/ [eitan@hadoop103 ~]$ echo 3 > /opt/module/zookeeper-3.5.7/zkData/myid [eitan@hadoop104 ~]$ echo 4 > /opt/module/zookeeper-3.5.7/zkData/myid
客户端命令行操作
命令基本语法
功能描述
help
显示所有操作命令
ls path
使用 ls 命令来查看当前 znode 的子节点
create
普通创建
get path
获得节点的值
set
设置节点的具体值
stat
查看节点状态
delete
删除节点
deleteall
递归删除节点
群起集群脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 [eitan@hadoop102 ~]$ vim ./bin/zk.sh # !/bin/bash case $1 in "start"){ for i in hadoop102 hadoop103 hadoop104 do echo ---------- zookeeper $i 启动 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start" done };; "stop"){ for i in hadoop102 hadoop103 hadoop104 do echo ---------- zookeeper $i 停止 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop" done };; "status"){ for i in hadoop102 hadoop103 hadoop104 do echo ---------- zookeeper $i 状态 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status" done };; esac [eitan@hadoop102 ~]$ chmod u+x ./bin/zk.sh [eitan@hadoop102 ~]$ xsync ./bin/zk.sh
Kafka 集群安装 上传并解压文件 1 2 3 [eitan@hadoop102 ~]$ tar -zxf /opt/software/kafka_2.11-2.4.1.tgz -C /opt/module/ [eitan@hadoop102 ~]$ mv /opt/module/kafka_2.11-2.4.1/ /opt/module/kafka
修改配置文件 1 2 3 4 5 6 7 8 9 [eitan@hadoop102 ~]$ vim /opt/module/kafka/config/server.properties # broker的全局唯一编号,不能重复 broker.id=0 # kafka 运行日志存放的路径 log.dirs=/opt/module/kafka/data # 配置连接 Zookeeper 集群地址 zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181/kafka
配置环境变量 1 2 3 4 5 6 [eitan@hadoop102 ~]$ sudo vim /etc/profile.d/my_env.sh # KAFKA_HOME export KAFKA_HOME=/opt/module/kafka export PATH=$PATH:$KAFKA_HOME/bin [eitan@hadoop102 ~]$ source /etc/profile
分发并修改broker.id 1 2 3 4 5 6 7 [eitan@hadoop102 ~]$ xsync /opt/module/kafka/ [eitan@hadoop103 ~]$ vim /opt/module/kafka/config/server.properties broker.id=1 [eitan@hadoop104 ~]$ vim /opt/module/kafka/config/server.properties broker.id=2
群起集群脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 [eitan@hadoop102 ~]$ vim ./bin/kf.sh # !/bin/bash case $1 in "start"){ for host in hadoop102 hadoop103 hadoop104 do echo " --------启动 $host Kafka-------" ssh $host "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties " done };; "stop"){ for host in hadoop102 hadoop103 hadoop104 do echo " --------停止 $host Kafka-------" ssh $host "/opt/module/kafka/bin/kafka-server-stop.sh stop" done };; esac [eitan@hadoop102 ~]$ chmod u+x ./bin/kf.sh
Kafka常用命令 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 # 1.查看Kafka Topic列表 [eitan@hadoop102 ~]$ kafka-topics.sh --bootstrap-server hadoop102:9092 --list # 2.创建Kafka Topic [eitan@hadoop102 ~]$ kafka-topics.sh --bootstrap-server hadoop102:9092 --create --topic first --partitions 1 --replication-factor 2 # 3.更改主题(只能改大分区) [eitan@hadoop102 ~]$ kafka-topics.sh --bootstrap-server hadoop102:9092 --alter --topic first --partitions 3 # 4.查看Kafka Topic详情 [eitan@hadoop102 ~]$ kafka-topics.sh --bootstrap-server hadoop102:9092 --describe --topic first Topic: first PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824 Topic: first Partition: 0 Leader: 1 Replicas: 1,0 Isr: 1,0 Topic: first Partition: 1 Leader: 2 Replicas: 2,1 Isr: 2,1 Topic: first Partition: 2 Leader: 0 Replicas: 0,2 Isr: 0,2 # 5.Kafka生产消息 [eitan@hadoop102 ~]$ kafka-console-producer.sh --broker-list hadoop102:9092 --topic first # 6.Kafka消费消息 [eitan@hadoop103 ~]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --from-beginning --topic first # 7.删除Kafka Topic [eitan@hadoop102 ~]$ kafka-topics.sh --bootstrap-server hadoop102:9092 --delete --topic first
Flume 安装 上传并解压文件 1 2 3 [eitan@hadoop102 ~]$ tar -zxf /opt/software/apache-flume-1.9.0-bin.tar.gz -C /opt/module/ [eitan@hadoop102 ~]$ mv /opt/module/apache-flume-1.9.0-bin/ /opt/module/flume
解决版本冲突 1 2 # 将lib文件夹下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3 [eitan@hadoop102 ~]$ rm /opt/module/flume/lib/guava-11.0.2.jar
注意:删除guava-11.0.2.jar的服务器节点,一定要配置hadoop环境变量。否则会报如下异常。
修改配置文件 1 2 3 # 修改日志文件路径 [eitan@hadoop102 ~]$ vim /opt/module/flume/conf/log4j.properties flume.log.dir=/opt/module/flume/logs
分发Flume 1 [eitan@hadoop102 ~]$ xsync /opt/module/flume/
日志采集 Flume 日志采集 Flume 配置概述 按照规划,需要采集的用户行为日志文件分布在 hadoop102,hadoop103 两台日志服务器,故需要在 hadoop102,hadoop103 两台节点配置日志采集 Flume。日志采集 Flume 需要采集日志文件内容,并对日志格式(JSON)进行校验,然后将校验通过的日志发送到Kafka。
此处可选择 TaildirSource 和 KafkaChannel,并配置日志校验拦截器。
TailDirSource:断点续传、多目录。Flume1.6以前需要自己自定义Source记录每次读取文件位置,实现断点续传;
KafkaChannel,省去了Sink,提高了效率。
日志采集 Flume 配置实操 配置文件编写 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 # Name the components on this agent a1.sources = r1 a1.channels = c1 # Describe/configure the source a1.sources.r1.type = TAILDIR a1.sources.r1.filegroups = f1 a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.* a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json # Interceptor a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.ETLInterceptor$Builder # Use a channel which buffers events in memory a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092 a1.channels.c1.kafka.topic = topic_log a1.channels.c1.parseAsFlumeEvent = false # Bind the source and sink to the channel a1.sources.r1.channels = c1
Flume 拦截器编写 创建 Maven 工程 flume-interceptor
在pom.xml文件中添加如下配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 <dependencies > <dependency > <groupId > org.apache.flume</groupId > <artifactId > flume-ng-core</artifactId > <version > 1.9.0</version > <scope > provided</scope > </dependency > <dependency > <groupId > com.alibaba</groupId > <artifactId > fastjson</artifactId > <version > 1.2.62</version > </dependency > </dependencies > <build > <plugins > <plugin > <artifactId > maven-compiler-plugin</artifactId > <version > 2.3.2</version > <configuration > <source > 1.8</source > <target > 1.8</target > </configuration > </plugin > <plugin > <artifactId > maven-assembly-plugin</artifactId > <configuration > <descriptorRefs > <descriptorRef > jar-with-dependencies</descriptorRef > </descriptorRefs > </configuration > <executions > <execution > <id > make-assembly</id > <phase > package</phase > <goals > <goal > single</goal > </goals > </execution > </executions > </plugin > </plugins > </build >
在 com.atguigu.flume.interceptor 包下创建 JSONUtils 类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 package com.atguigu.flume.interceptor;import com.alibaba.fastjson.JSON;import com.alibaba.fastjson.JSONException;public class JSONUtils public static boolean isJSONValidate (String str) try { JSON.parse(str); return true ; } catch (JSONException e) { return false ; } } }
在 com.atguigu.flume.interceptor 包下创建 ETLInterceptor 类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 package com.atguigu.flume.interceptor;import org.apache.flume.Context;import org.apache.flume.Event;import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets;import java.util.Iterator;import java.util.List;public class ETLInterceptor implements Interceptor @Override public void initialize () } @Override public Event intercept (Event event) byte [] body = event.getBody(); String log = new String(body, StandardCharsets.UTF_8); return JSONUtils.isJSONValidate(log) ? event : null ; } @Override public List<Event> intercept (List<Event> list) Iterator<Event> iterator = list.iterator(); while (iterator.hasNext()) { Event event = iterator.next(); if (intercept(event) == null ) { iterator.remove(); } } return list; } @Override public void close () } public static class Builder implements Interceptor .Builder @Override public Interceptor build () return new ETLInterceptor(); } @Override public void configure (Context context) } } }
打包并上传到 /opt/module/flume/lib 文件夹下面
修改配置文件添加拦截器
1 2 3 4 [eitan@hadoop102 ~]$ vim /opt/module/flume/job/file_to_kafka.conf # Interceptor a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.ETLInterceptor$Builder
分发
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 [eitan@hadoop102 ~]$ xsync /opt/module/flume/ ================ hadoop102 ================ sending incremental file list sent 56,235 bytes received 174 bytes 112,818.00 bytes/sec total size is 99,804,505 speedup is 1,769.30 ================ hadoop103 ================ sending incremental file list flume/ flume/job/ flume/job/file_to_kafka.conf flume/lib/ flume/lib/flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar sent 720,439 bytes received 231 bytes 1,441,340.00 bytes/sec total size is 99,804,505 speedup is 138.49 ================ hadoop104 ================ sending incremental file list flume/ flume/job/ flume/job/file_to_kafka.conf flume/lib/ flume/lib/flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar sent 720,435 bytes received 231 bytes 480,444.00 bytes/sec total size is 99,804,505 speedup is 138.49
日志采集 Flume 测试 启动 Zookeeper、Kafka 集群 1 2 3 4 5 6 7 8 9 10 11 12 13 [eitan@hadoop102 ~]$ zk.sh start [eitan@hadoop102 ~]$ kf.sh start [eitan@hadoop102 ~]$ jpsall --------- hadoop102 ---------- 10858 Kafka 10475 QuorumPeerMain --------- hadoop103 ---------- 10212 QuorumPeerMain 10598 Kafka --------- hadoop104 ---------- 8154 Kafka 7775 QuorumPeerMain
创建并监听 topic_log 1 2 3 [eitan@hadoop102 ~]$ kafka-topics.sh --bootstrap-server hadoop102:9092 --create --topic topic_log --partitions 3 --replication-factor 2 [eitan@hadoop102 ~]$ kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic topic_log
启动 hadoop102 的日志采集Flume 1 2 [eitan@hadoop102 ~]$ cd /opt/module/flume/ [eitan@hadoop102 flume]$ ./bin/flume-ng agent -c conf/ -f job/file_to_kafka.conf -n a1 -Dflume.root.logger=info,console
生成模拟数据并观察 1 [eitan@hadoop102 ~]$ lg.sh
日志采集Flume启停脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 [eitan@hadoop102 ~]$ vim ./bin/f1.sh # !/bin/bash case $1 in "start"){ for i in hadoop102 hadoop103 do echo " --------启动 $i 采集flume-------" ssh $i "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/file_to_kafka.conf >/dev/null 2>&1 &" done };; "stop"){ for i in hadoop102 hadoop103 do echo " --------停止 $i 采集flume-------" ssh $i "ps -ef | grep file_to_kafka.conf | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 " done };; esac [eitan@hadoop102 ~]$ chmod u+x ./bin/f1.sh [eitan@hadoop102 ~]$ xsync ./bin/f1.sh
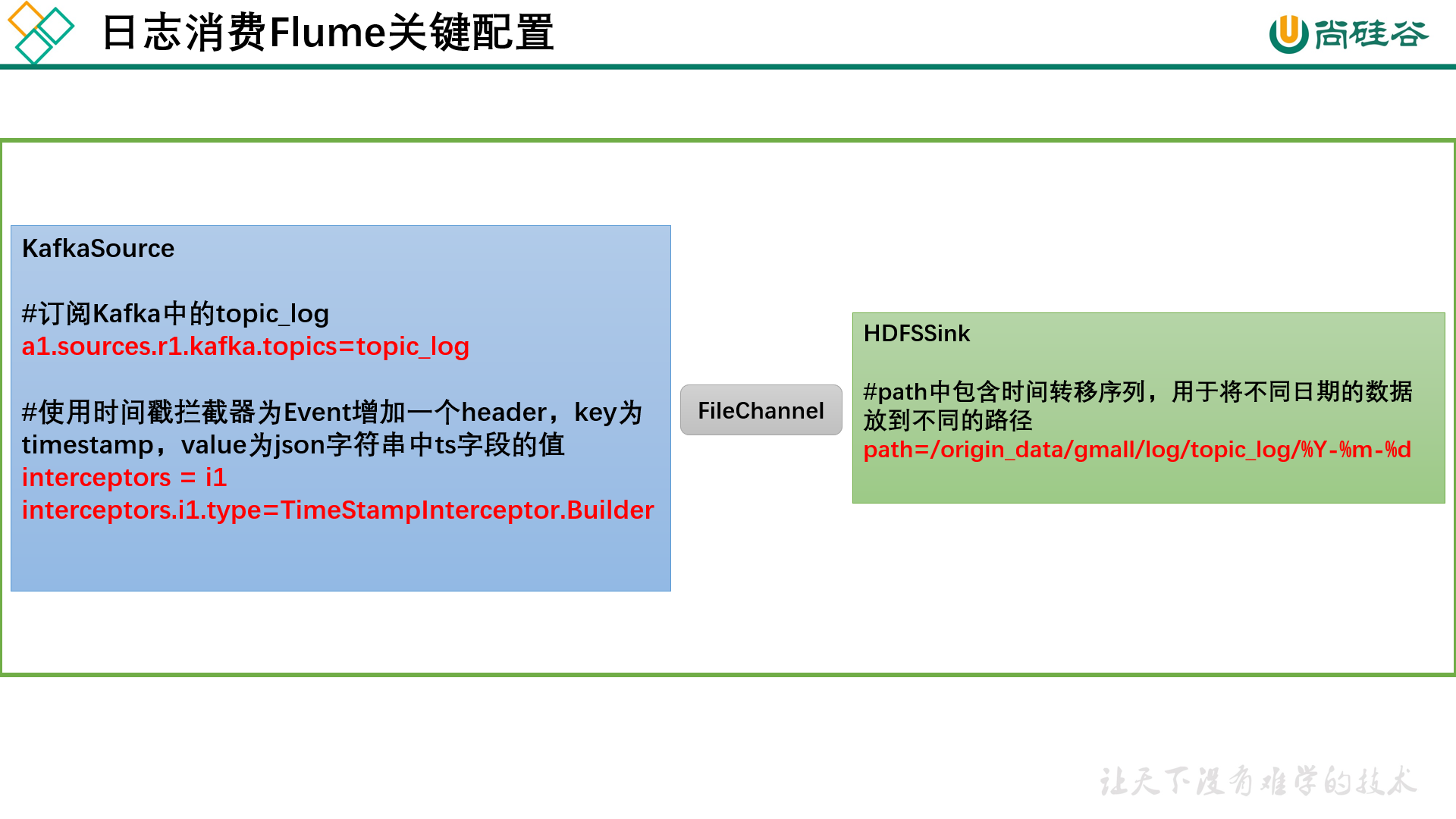
日志消费 Flume 日志消费 Flume 配置概述 按照规划,该 Flume 需将 Kafka 中 topic_log 的数据发往 HDFS。并且对每天产生的用户行为日志进行区分,将不同天的数据发往 HDFS不同天的路径。此处选择 KafkaSource、FileChannel、HDFSSink。
日志消费 Flume 配置实操 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 [eitan@hadoop102 ~]$ vim /opt/module/flume/job/kafka_to_hdfs.conf # a1.sources=r1 a1.channels=c1 a1.sinks=k1 # source a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sources.r1.kafka.consumer.group.id = flume2 a1.sources.r1.kafka.topics = topic_log a1.sources.r1.batchSize = 5000 a1.sources.r1.batchDurationMillis = 2000 # Interceptor a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimeStampInterceptor$Builder # channel a1.channels.c1.type = file a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1 a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/ a1.channels.c1.maxFileSize = 2146435071 a1.channels.c1.capacity = 1000000 a1.channels.c1.keep-alive = 6 # sink1 a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d a1.sinks.k1.hdfs.filePrefix = log- a1.sinks.k1.hdfs.rollInterval = 10 a1.sinks.k1.hdfs.rollSize = 134217728 a1.sinks.k1.hdfs.rollCount = 0 # 控制输出文件是原生文件 a1.sinks.k1.hdfs.fileType = CompressedStream a1.sinks.k1.hdfs.codeC = gzip # 拼装 a1.sources.r1.channels = c1 a1.sinks.k1.channel= c1
配置优化
编写 Flume 拦截器 在 com.atguigu.flume.interceptor 包下创建 TimeStampInterceptor 类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 package com.atguigu.flume.interceptor;import com.alibaba.fastjson.JSONObject;import org.apache.flume.Event;import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets;import java.util.List;import java.util.Map;public class TimeStampInterceptor implements Interceptor @Override public void initialize () } @Override public Event intercept (Event event) byte [] body = event.getBody(); String log = new String(body, StandardCharsets.UTF_8); JSONObject jsonObject = JSONObject.parseObject(log); String ts = jsonObject.getString("ts" ); Map<String, String> headers = event.getHeaders(); headers.put("timestamp" , ts); return event; } @Override public List<Event> intercept (List<Event> list) for (Event event : list) { intercept(event); } return list; } @Override public void close () } }
打包并上传
修改配置文件添加拦截器
1 2 3 4 [eitan@hadoop102 ~]$ vim /opt/module/flume/job/kafka_to_hdfs.conf # Interceptor a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.atguigu.flume.interceptor.TimeStampInterceptor$Builder
日志消费Flume测试 启动 Hadoop、Zookeeper、Kafka 集群 1 2 3 4 5 6 7 8 9 10 11 12 13 [eitan@hadoop102 ~]$ zk.sh start [eitan@hadoop102 ~]$ kf.sh start [eitan@hadoop102 ~]$ jpsall --------- hadoop102 ---------- 10858 Kafka 10475 QuorumPeerMain --------- hadoop103 ---------- 10212 QuorumPeerMain 10598 Kafka --------- hadoop104 ---------- 8154 Kafka 7775 QuorumPeerMain
启动 hadoop104 的日志消费 Flume 1 [eitan@hadoop104 ~]$ /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf/ -f /opt/module/flume/job/kafka_to_hdfs.conf -Dflume.root.logger=info,console
生成模拟数据 1 2 [eitan@hadoop102 ~]$ f1.sh [eitan@hadoop102 ~]$ lg.sh
日志消费Flume启停脚本 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [eitan@hadoop102 ~]$ vim ./bin/f2.sh # !/bin/bash case $1 in "start") echo " --------启动 hadoop104 日志数据flume-------" ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs.conf >/dev/null 2>&1 &" ;; "stop") echo " --------停止 hadoop104 日志数据flume-------" ssh hadoop104 "ps -ef | grep kafka_to_hdfs.conf | grep -v grep |awk '{print \$2}' | xargs -n1 kill" ;; esac [eitan@hadoop102 ~]$ chmod u+x ./bin/f2.sh [eitan@hadoop102 ~]$ xsync ./bin/f2.sh