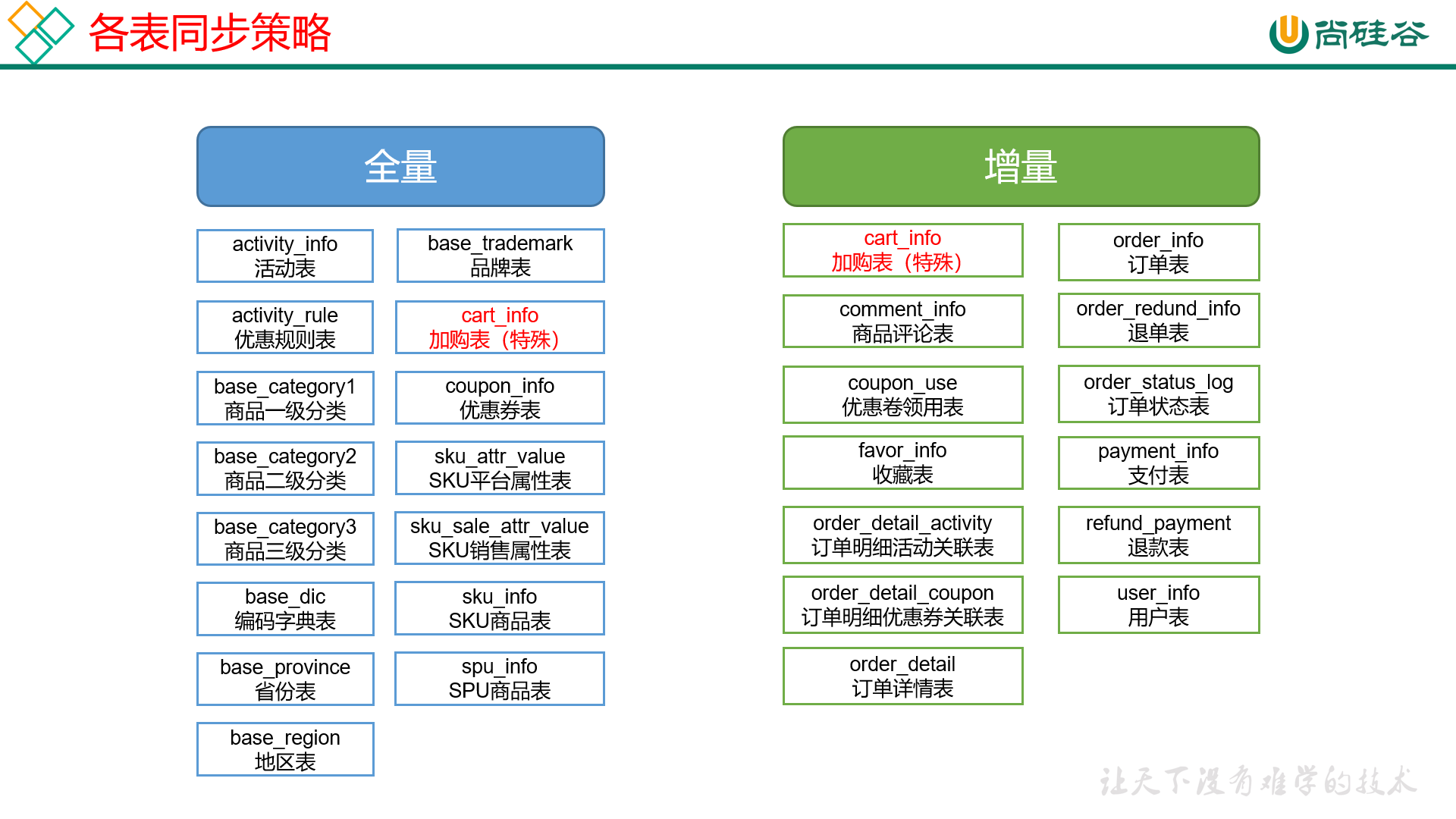
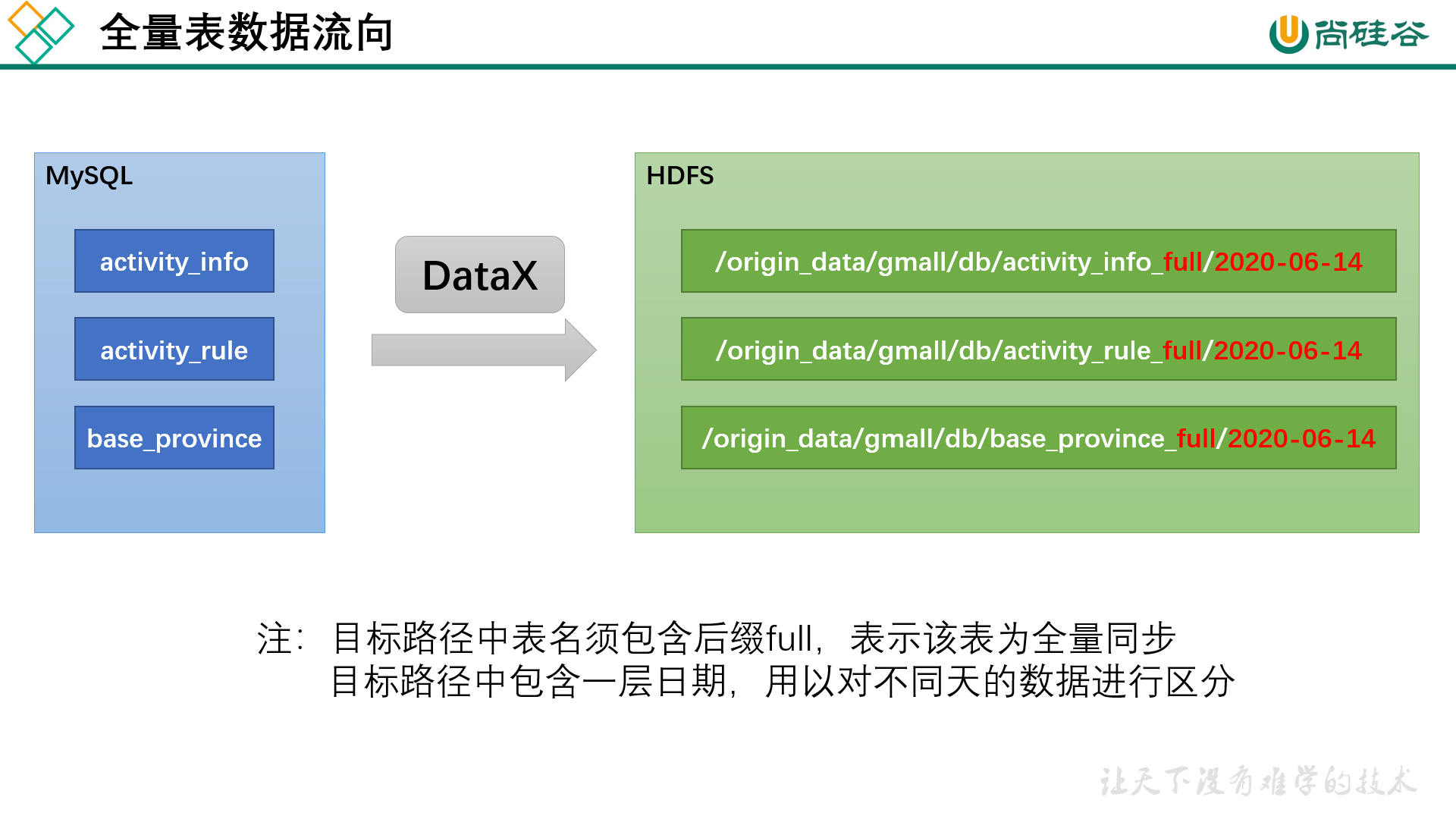
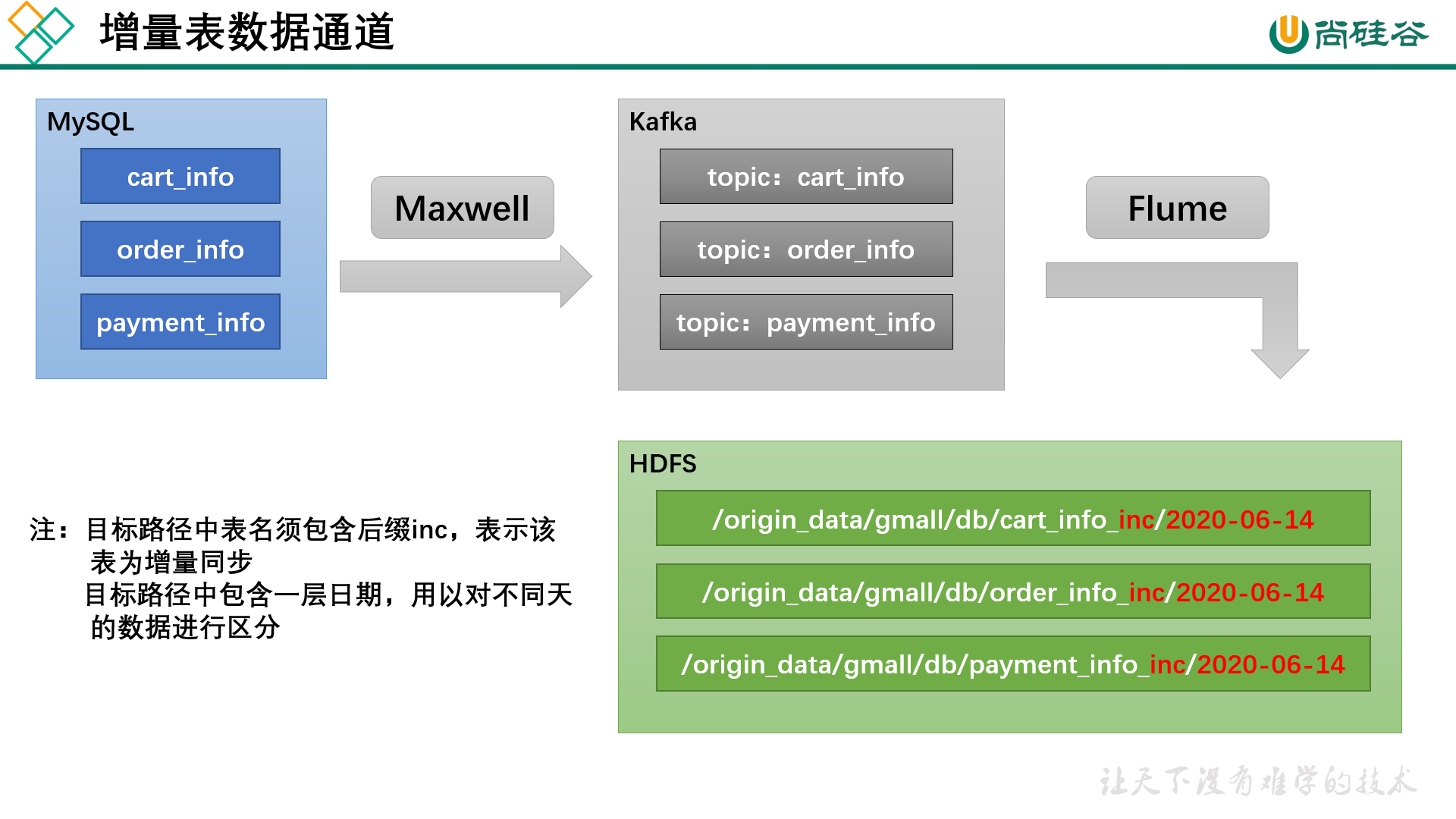
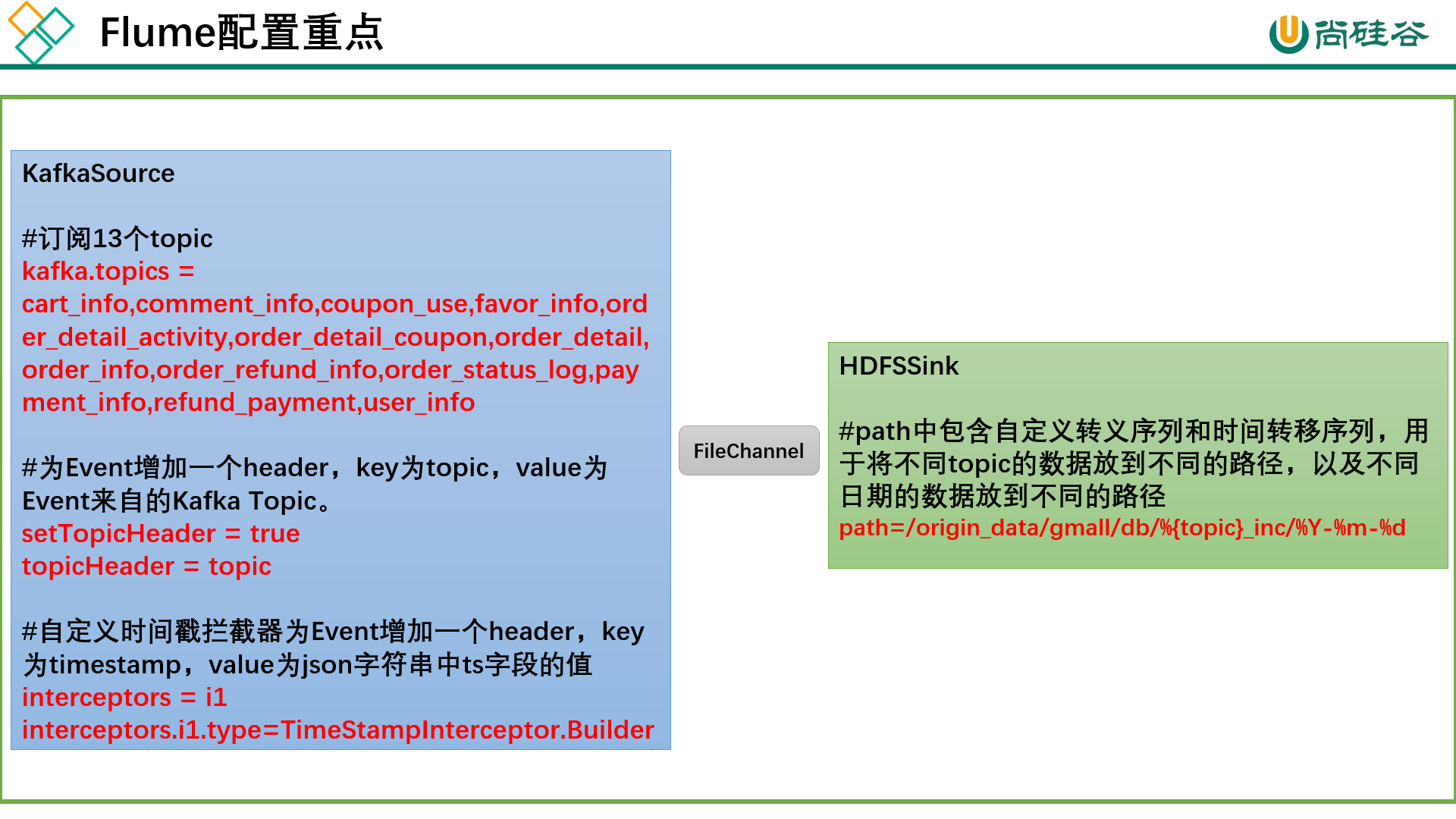
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
|
import json
import getopt
import os
import sys
import MySQLdb
mysql_host = "hadoop102"
mysql_port = "3306"
mysql_user = "root"
mysql_passwd = "root"
hdfs_nn_host = "hadoop102"
hdfs_nn_port = "8020"
output_path = "/opt/module/datax/job/import"
def get_connection():
return MySQLdb.connect(host=mysql_host, port=int(mysql_port), user=mysql_user, passwd=mysql_passwd)
def get_mysql_meta(database, table):
connection = get_connection()
cursor = connection.cursor()
sql = "SELECT COLUMN_NAME,DATA_TYPE from information_schema.COLUMNS WHERE TABLE_SCHEMA=%s AND TABLE_NAME=%s ORDER BY ORDINAL_POSITION"
cursor.execute(sql, [database, table])
fetchall = cursor.fetchall()
cursor.close()
connection.close()
return fetchall
def get_mysql_columns(database, table):
return map(lambda x: x[0], get_mysql_meta(database, table))
def get_hive_columns(database, table):
def type_mapping(mysql_type):
mappings = {
"bigint": "bigint",
"int": "bigint",
"smallint": "bigint",
"tinyint": "bigint",
"decimal": "string",
"double": "double",
"float": "float",
"binary": "string",
"char": "string",
"varchar": "string",
"datetime": "string",
"time": "string",
"timestamp": "string",
"date": "string",
"text": "string"
}
return mappings[mysql_type]
meta = get_mysql_meta(database, table)
return map(lambda x: {"name": x[0], "type": type_mapping(x[1].lower())}, meta)
def generate_json(source_database, source_table):
job = {
"job": {
"setting": {
"speed": {
"channel": 3
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": mysql_user,
"password": mysql_passwd,
"column": get_mysql_columns(source_database, source_table),
"splitPk": "",
"connection": [{
"table": [source_table],
"jdbcUrl": ["jdbc:mysql://" + mysql_host + ":" + mysql_port + "/" + source_database]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"defaultFS": "hdfs://" + hdfs_nn_host + ":" + hdfs_nn_port,
"fileType": "text",
"path": "${targetdir}",
"fileName": source_table,
"column": get_hive_columns(source_database, source_table),
"writeMode": "append",
"fieldDelimiter": "\t",
"compress": "gzip"
}
}
}]
}
}
if not os.path.exists(output_path):
os.makedirs(output_path)
with open(os.path.join(output_path, ".".join([source_database, source_table, "json"])), "w") as f:
json.dump(job, f)
def main(args):
source_database = ""
source_table = ""
options, arguments = getopt.getopt(args, '-d:-t:', ['sourcedb=', 'sourcetbl='])
for opt_name, opt_value in options:
if opt_name in ('-d', '--sourcedb'):
source_database = opt_value
if opt_name in ('-t', '--sourcetbl'):
source_table = opt_value
generate_json(source_database, source_table)
if __name__ == '__main__':
main(sys.argv[1:])
|