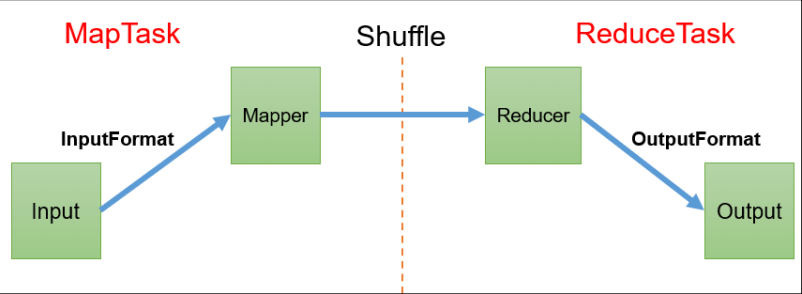
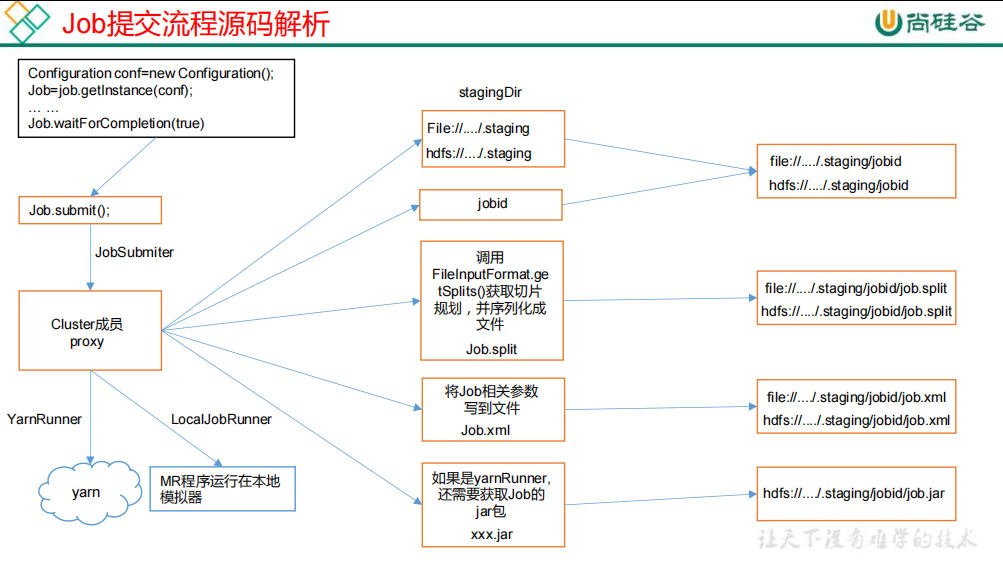
/** * Submit the job to the cluster and wait for it to finish. * @param verbose print the progress to the user * @return true if the job succeeded * @throws IOException thrown if the communication with the * <code>JobTracker</code> is lost */ publicbooleanwaitForCompletion(boolean verbose )throws IOException, InterruptedException, ClassNotFoundException { if (state == JobState.DEFINE) { submit(); } if (verbose) { monitorAndPrintJob(); } else { // get the completion poll interval from the client. int completionPollIntervalMillis = Job.getCompletionPollInterval(cluster.getConf()); while (!isComplete()) { try { Thread.sleep(completionPollIntervalMillis); } catch (InterruptedException ie) { } } } return isSuccessful(); }
// 1.初始化暂存目录并返回路径,该路径下存放的是提交任务的相关信息。 Path jobStagingArea = JobSubmissionFiles.getStagingDir(cluster, conf); ... // 2.获取jobid JobID jobId = submitClient.getNewJobID(); job.setJobID(jobId); Path submitJobDir = new Path(jobStagingArea, jobId.toString()); try { ... // 3.configure the jobconf of the user with the command line options of -libjars, -files, -archives. copyAndConfigureFiles(job, submitJobDir);
// sort the splits into order based on size, so that the biggest // go first Arrays.sort(array, new SplitComparator()); JobSplitWriter.createSplitFiles(jobSubmitDir, conf, jobSubmitDir.getFileSystem(conf), array); return array.length; }
public List<InputSplit> getSplits(JobContext job)throws IOException { StopWatch sw = new StopWatch().start(); long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job)); long maxSize = getMaxSplitSize(job);
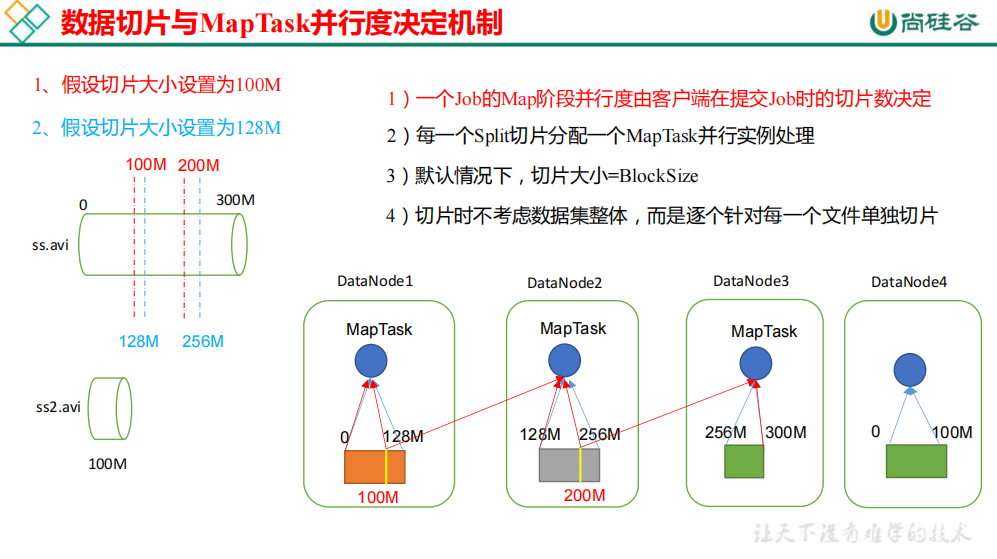
boolean ignoreDirs = !getInputDirRecursive(job) && job.getConfiguration().getBoolean(INPUT_DIR_NONRECURSIVE_IGNORE_SUBDIRS, false); // 遍历文件,这里可以判断出切片不是考虑数据集整体,而是针对每一个文件单独切片 for (FileStatus file: files) { if (ignoreDirs && file.isDirectory()) { continue; } Path path = file.getPath(); // 获取文件长度 long length = file.getLen(); if (length != 0) { BlockLocation[] blkLocations; if (file instanceof LocatedFileStatus) { blkLocations = ((LocatedFileStatus) file).getBlockLocations(); } else { FileSystem fs = path.getFileSystem(job.getConfiguration()); blkLocations = fs.getFileBlockLocations(file, 0, length); } // 判断该文件是否可以切片,有些压缩过的文件不支持切片 if (isSplitable(job, path)) { long blockSize = file.getBlockSize(); // 计算切片大小,默认等于blockSize long splitSize = computeSplitSize(blockSize, minSize, maxSize);
long bytesRemaining = length; // SPLIT_SLOP为1.1,即当文件剩余大小小于块文件的1.1倍时,不进行切片避免产生小文件 while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); // 将切片信息记入在splits数组中 splits.add(makeSplit(path, length-bytesRemaining, splitSize, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); bytesRemaining -= splitSize; }
if (bytesRemaining != 0) { int blkIndex = getBlockIndex(blkLocations, length-bytesRemaining); splits.add(makeSplit(path, length-bytesRemaining, bytesRemaining, blkLocations[blkIndex].getHosts(), blkLocations[blkIndex].getCachedHosts())); } } else { // not splitable if (LOG.isDebugEnabled()) { // Log only if the file is big enough to be splitted if (length > Math.min(file.getBlockSize(), minSize)) { LOG.debug("File is not splittable so no parallelization " + "is possible: " + file.getPath()); } } splits.add(makeSplit(path, 0, length, blkLocations[0].getHosts(), blkLocations[0].getCachedHosts())); } } else { //Create empty hosts array for zero length files splits.add(makeSplit(path, 0, length, new String[0])); } } // Save the number of input files for metrics/loadgen job.getConfiguration().setLong(NUM_INPUT_FILES, files.size()); sw.stop(); if (LOG.isDebugEnabled()) { LOG.debug("Total # of splits generated by getSplits: " + splits.size() + ", TimeTaken: " + sw.now(TimeUnit.MILLISECONDS)); } return splits; }
privateintreadDefaultLine(Text str, int maxLineLength, int maxBytesToConsume) throws IOException { /* We're reading data from in, but the head of the stream may be * already buffered in buffer, so we have several cases: * 1. No newline characters are in the buffer, so we need to copy * everything and read another buffer from the stream. * 2. An unambiguously terminated line is in buffer, so we just * copy to str. * 3. Ambiguously terminated line is in buffer, i.e. buffer ends * in CR. In this case we copy everything up to CR to str, but * we also need to see what follows CR: if it's LF, then we * need consume LF as well, so next call to readLine will read * from after that. * We use a flag prevCharCR to signal if previous character was CR * and, if it happens to be at the end of the buffer, delay * consuming it until we have a chance to look at the char that * follows. */ str.clear(); int txtLength = 0; //tracks str.getLength(), as an optimization int newlineLength = 0; //length of terminating newline boolean prevCharCR = false; //true of prev char was CR long bytesConsumed = 0; do { int startPosn = bufferPosn; //starting from where we left off the last time if (bufferPosn >= bufferLength) { startPosn = bufferPosn = 0; if (prevCharCR) { ++bytesConsumed; //account for CR from previous read } bufferLength = fillBuffer(in, buffer, prevCharCR); if (bufferLength <= 0) { break; // EOF } } for (; bufferPosn < bufferLength; ++bufferPosn) { //search for newline if (buffer[bufferPosn] == LF) { newlineLength = (prevCharCR) ? 2 : 1; ++bufferPosn; // at next invocation proceed from following byte break; } if (prevCharCR) { //CR + notLF, we are at notLF newlineLength = 1; break; } prevCharCR = (buffer[bufferPosn] == CR); } int readLength = bufferPosn - startPosn; if (prevCharCR && newlineLength == 0) { --readLength; //CR at the end of the buffer } bytesConsumed += readLength; int appendLength = readLength - newlineLength; if (appendLength > maxLineLength - txtLength) { appendLength = maxLineLength - txtLength; } if (appendLength > 0) { str.append(buffer, startPosn, appendLength); txtLength += appendLength; } } while (newlineLength == 0 && bytesConsumed < maxBytesToConsume);
if (bytesConsumed > Integer.MAX_VALUE) { thrownew IOException("Too many bytes before newline: " + bytesConsumed); } return (int)bytesConsumed; }
publicbooleannextKeyValue()throws IOException { if (key == null) { key = new LongWritable(); } key.set(pos); if (value == null) { value = new Text(); } int newSize = 0; // We always read one extra line, which lies outside the upper // split limit i.e. (end - 1) while (getFilePosition() <= end || in.needAdditionalRecordAfterSplit()) { if (pos == 0) { newSize = skipUtfByteOrderMark(); } else { newSize = in.readLine(value, maxLineLength, maxBytesToConsume(pos)); pos += newSize; }
// If this is not the first split, we always throw away first record // because we always (except the last split) read one extra line in // next() method. if (start != 0) { start += in.readLine(new Text(), 0, maxBytesToConsume(start)); } this.pos = start;